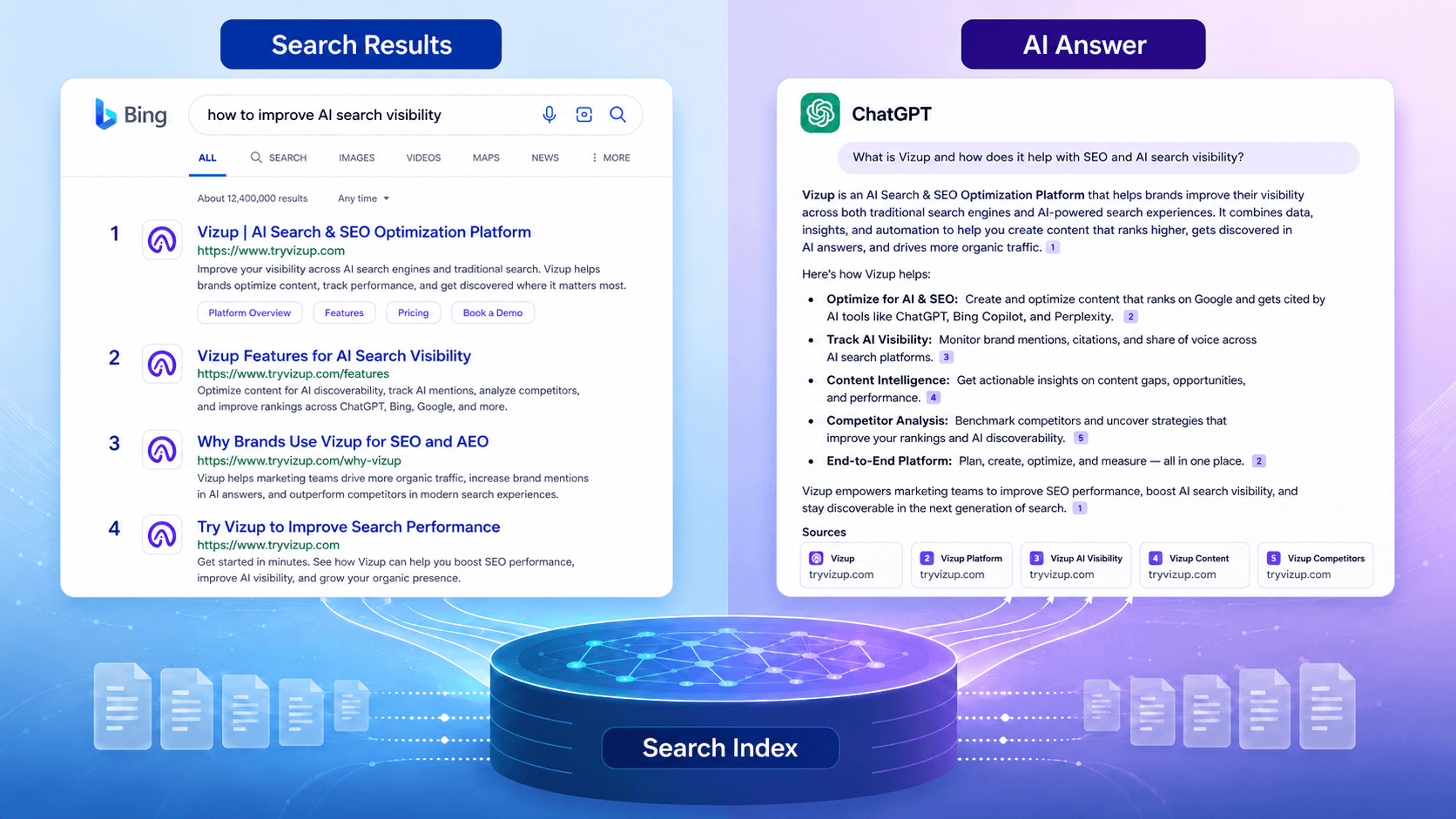
Content teams have been running into a maddening pattern: pages that do great in Bing’s classic results never show up as citations when Copilot or ChatGPT answers the same question. Then you’ll see the opposite, where a mid-ranking page becomes the one an AI latches onto. If that mismatch has been driving you nuts, it’s the gap between Bing AI grounding vs search indexing.
This isn’t a theoretical SEO argument. Gartner projects roughly 25% of search behavior will shift toward AI-driven answers by the end of 2026. ChatGPT’s web-connected mode runs on the Bing index. About 60% of Fortune 500 companies now have Copilot deployments. The same content is being judged by two systems that share infrastructure but chase different outcomes, and most teams are still optimizing as if there’s only one. Below is how indexing works, how grounding differs, and what to change in content, measurement, and day-to-day ops.
What 'search indexing' actually does (skip this if you've been doing SEO for 5+ years)
The old pipeline still applies: crawl, index, rank. A crawler finds your page, the indexer stores a representation of it (content, links, structured data, freshness signals), and the ranking system decides where it lands for a query. The index is the retrieval layer; ranking is the ordering layer. Mixing those up leads to bad calls, fast.
“Indexed” is not the same thing as “seen.” A URL can sit in Bing’s index and never crack the top 50 for any query that matters, thanks to SERP features, personalization, or simple intent mismatch. If you need to sanity-check indexation at scale, tools for bulk index checking can help. Just don’t mistake coverage for performance.
Bing AI grounding vs search indexing: two systems, two jobs
Microsoft puts it plainly: traditional search indexing and AI grounding “are built on the same foundations but are optimized for different problems. Traditional search asks, which pages should a user visit? Grounding asks, what information can an AI system responsibly use to construct a response?” (Microsoft Bing Blogs, 2026). That one split explains a lot of the weirdness content strategists are seeing.
Grounding is citation-backed answer generation. Bing’s “Bing Orchestrator” brokers between the live search index and the GPT model, pulling from index data so the AI can answer with current context and citations (Search Engine Journal, 2023). The upshot is counterintuitive: you can be indexed and still not be groundable, and you can get grounded without owning the #1 spot. Jordi Ribas, CVP of Search & AI at Microsoft, has stressed that grounded answers have to trace back to verifiable sources, with citation quality treated as a first-class requirement for AI surfaces.
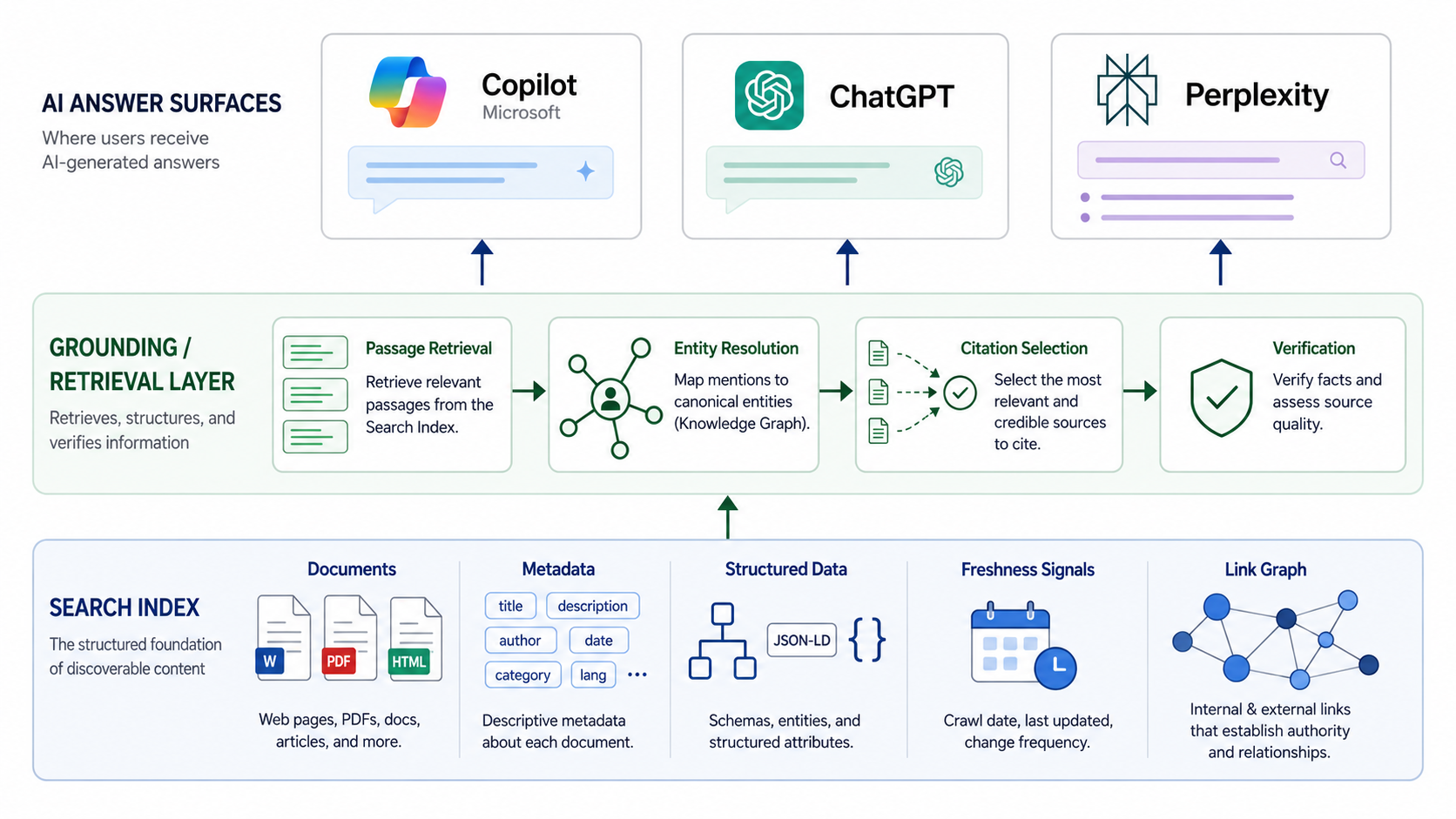
What the search index keeps vs what grounding looks for
The search index hangs onto canonical content, link graphs, structured data, and a pile of quality heuristics. Technical hygiene (canonicals, redirects, crawl paths) decides what’s even eligible to compete. Grounding cares less about the whole document and more about what it can reliably retrieve: clean passages, unambiguous entities, and URLs that don’t wobble. Traditional search values the page. For AI grounding, the unit of value is “groundable information”, discrete, checkable facts tied to clear sources (Search Engine Roundtable, 2026). Content that reads like an answer tends to win because the model needs something it can lift and attribute, not just a page it can point to.
Even then, attribution can get weird. The system can use your information and still cite someone else (or nothing) depending on the answer surface and its policies. Teams feel that pain most when they publish original research and watch a secondary source get the credit because it packaged the same data in a more extractable way.
What most people get wrong
“If I rank, I’ll be cited.” Sometimes, not consistently. “AI ignores SEO.” Also wrong, because retrieval still depends on crawlable, indexable pages. These are half-truths that push teams toward the extremes: either they pretend grounding doesn’t matter, or they ditch SEO basics. The actual situation is messier, and that’s what makes it dangerous.
The citation gap usually comes down to passage quality. AI systems favor blocks that resolve the question cleanly, not pages that merely match keywords. A 3,000-word guide full of throat-clearing can lose to a 70-word definition that hits the prompt dead-on. Grounding systems also have to reconcile contradictions across sources before producing an answer; traditional search can rank conflicting pages and let the user sort it out (Search Engine Land, 2026). In classic search, a stale fact is mostly a ranking-quality issue. In a grounded answer, that same stale fact becomes misinformation (Search Engine Journal, 2026).
Note: The next SEO moat isn’t a one-time on-page sweep. It’s how quickly you can measure and iterate across both indexing and grounding surfaces.
How your content strategy actually changes
The mindset shift is from “page targets keyword” to “page resolves a question with passages worth citing.” That sounds minor until you try to execute it: it changes page structure, what evidence you bother to include, and what “success” even means. If you’re building AI content strategy frameworks, grounding readiness belongs in the framework from day one, not as a retrofit after rankings plateau.

Write passage-first sections
Build sections around tight 40–80 word blocks that can stand on their own. Start with the conclusion, then add the qualifier. A simple gut check: if someone yanked that paragraph out of the page and pasted it into a chat answer, would it still read clearly? Structure your H2/H3s so each section answers one question. And keep entity terms consistent across the page; retrieval systems are far less forgiving about synonyms than you’d like.
Add evidence the model can trust
Use primary sources. Put dates on claims. Skip vague filler like “studies show” unless you name the study. When you include stats, format them so they’re easy to quote: “60% of Fortune 500 companies use Copilot (Microsoft, 2026)” is extractable; “most enterprises are adopting AI assistants” isn’t. For YMYL-adjacent topics especially, author bios, editorial policies, and a visible update cadence help both ranking and grounding systems judge trustworthiness. Learning how to make content discoverable in AI engines starts with making your evidence checkable.
Make entity relationships explicit
Spell out product/category/brand relationships instead of assuming the reader (or the model) will infer them. Define acronyms once, clearly. If you write “AEO” in one section and “Answer Engine Optimization” in another without connecting the two, the retrieval layer has to guess. Use structured data where it genuinely fits (Organization, Product, FAQ, HowTo), and resist the urge to carpet-bomb pages with schema. Markup is a signal, not a magic bypass.
Grounding Readiness Checklist
Five content signals that improve grounding eligibility:
- Clear, extractable answer passages. Definition blocks, step sequences, and comparison tables that can be lifted into an answer without losing meaning.
- Strong entity clarity. Consistent naming, disambiguation of similar terms, explicit who/what/where references throughout the page.
- Verifiable evidence. Primary sources cited inline, dates included, methodology notes where applicable. No orphan statistics.
- Technical accessibility. Indexable pages, fast load times, clean canonicals, stable URLs that don’t redirect or break.
- Freshness and stewardship. Update logs, “last reviewed” dates, visible content ownership. Stale pages get deprioritized for grounding even if they still rank.
Measurement that doesn't lie: the 5-area framework
There isn’t one dashboard that shows “grounding” end to end, so you need a measurement model that breaks the problem into five parts. Too many teams obsess over rankings while having no idea whether Copilot is citing them at all. That’s like counting people who walk into a store and never checking the receipts.
Areas 1-2: Index coverage and rank visibility. The familiar layer: indexation health (coverage, canonicals, crawl stats) plus rank tracking for core queries. A common trap: you can improve rankings while hurting grounding if your “optimization” makes the page less answer-shaped. Area 3: Grounded citations across AI answer surfaces. Track whether you’re cited, where (Copilot, Perplexity, AI Overviews, ChatGPT), and for which prompts. Save citation URLs and map them back to the specific passages being pulled. This is where AI search visibility optimization stops being a buzz phrase and becomes a workflow. Areas 4-5: On-site engagement and conversion impact. Look at scroll depth on answer blocks, internal CTR, assisted conversions, lead quality, and pipeline influence from AI-sourced visits.
Vizup’s Watcher Agent covers Area 3 by monitoring brand visibility across grounding surfaces, including ChatGPT (Bing-indexed), Copilot, Perplexity, and Google AI Overviews. The Strategist Agent turns grounding-gap findings into prioritized recommendations. Weekly citation checks and monthly share-of-voice reporting, the layer many teams don’t measure at all.
The 'ranked but not grounded' problem
Picture a marketing analytics page sitting in the top five in Bing for its target keyword, and still never showing up in Copilot citations for the same topic. That pattern shows up a lot. The diagnosis is usually boring: the content is long, vague, and light on extractable passages and primary-source evidence. It reads like thought leadership when the AI is hunting for a reference.
The fix usually isn’t a full rewrite. Add a 70-word definition block near the top. Drop in a comparison table. Include a dated methodology section. Then check citations with a tool like Vizup’s Watcher Agent to confirm the change actually mattered. Google’s AI features are moving in similar directions; understanding Google Search Live for AI Mode makes it clear this isn’t just a Bing quirk.
Edge cases that decide who gets cited
Prompts are touchy. Tiny wording changes can reshuffle citations. Treat prompt sets like test suites: build 10–15 variations of the same question, run them monthly, and track which version of your content gets pulled. Some brands end up with “implied grounding,” where their facts show up but no citation does. It’s harder to spot and harder to fix, and it often means your material is being synthesized rather than quoted. The practical response is to make passages more distinctive and easier to quote directly. An AI content checker can help flag sections that read too generic to earn attribution.
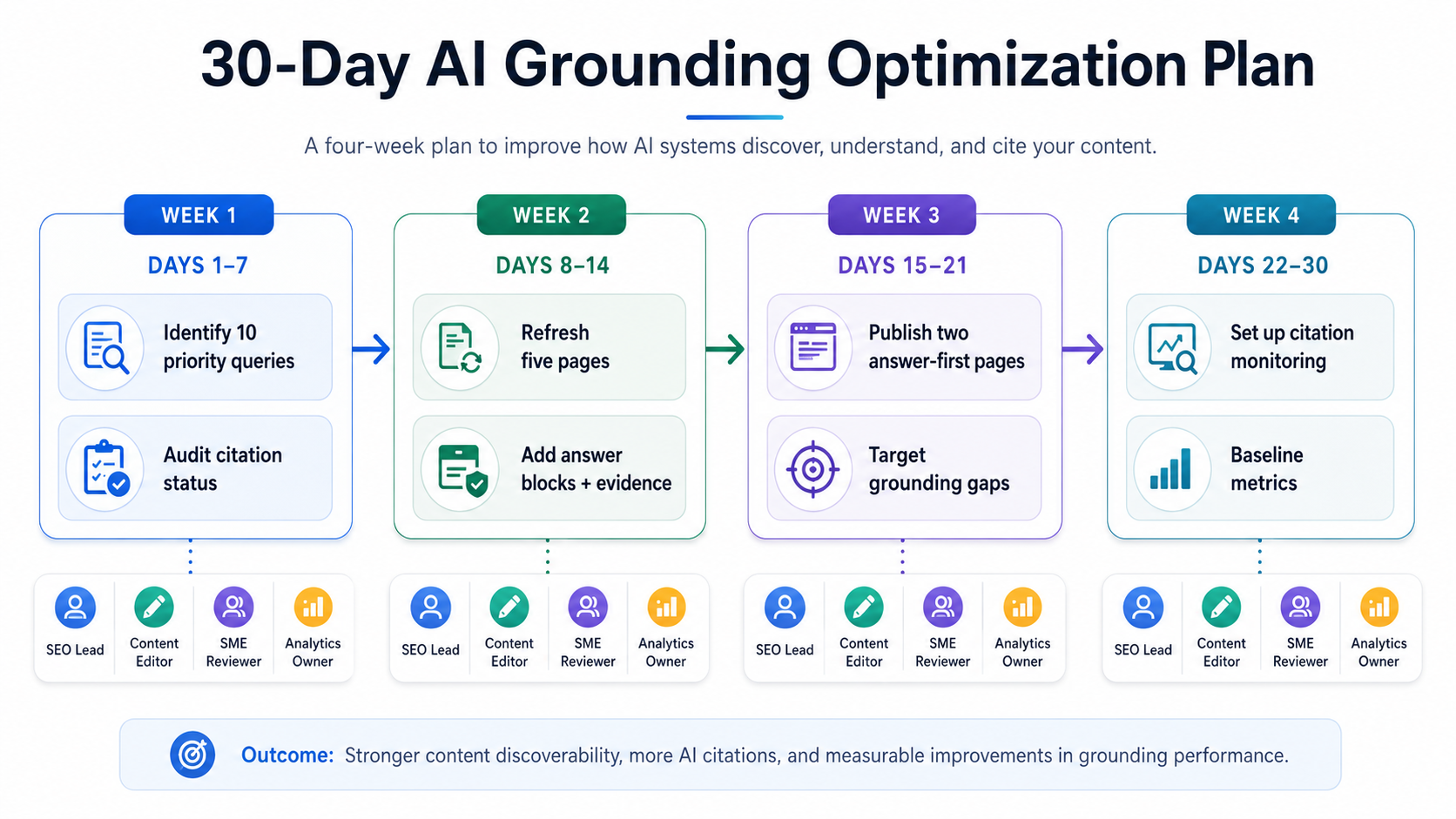
Operationalizing it: 30 days, not 30 months
Week 1: Choose 10 priority queries where you rank but don’t get cited. Audit those pages against the Grounding Readiness Checklist. Week 2: Refresh five pages with answer blocks, cleaner evidence formatting, and tighter entity consistency. Week 3: Publish two new answer-first pages aimed at grounding gaps your monitoring uncovered. Week 4: Turn on citation monitoring across Copilot, ChatGPT, Perplexity, and AI Overviews, then lock in baselines.
Make ownership explicit. The SEO lead owns indexation and rank tracking. The content editor owns passage-level rewrites. A subject-matter reviewer signs off on evidence and freshness. The analytics owner ties citation data to engagement and conversion. You don’t need a sprawling org chart; you need names next to responsibilities.
Frequently Asked Questions
Is Bing AI grounding the same as being indexed in Bing?
No. Indexing means Bing has stored a representation of your page. Grounding means the AI system believes your page contains verifiable, extractable information it can use responsibly in a generated answer. A URL can be indexed and never get grounded. The infrastructure overlaps; the purpose doesn’t.
If ChatGPT uses the Bing index, does ranking in Bing guarantee citations in ChatGPT?
No. ChatGPT’s web-connected mode retrieves from the Bing index, but it still judges passage quality, entity clarity, and evidence strength before it decides what to cite. A page ranking #3 might never appear in citations if it isn’t written in extractable, answer-shaped blocks.
What’s the fastest way to improve grounding eligibility without rewriting the whole site?
Start with your five to 10 most important pages by traffic or strategic value. Add a 40–80 word definition or summary block near the top. Include dated, sourced statistics. Tighten entity references so terms don’t drift. That’s usually a few hours per page and can materially improve grounding eligibility without a rebuild.
How do I measure share of voice in Copilot, Perplexity, and AI Overviews if they don’t provide analytics?
You have to monitor externally. Tools like Vizup’s Watcher Agent track whether your brand is cited across these surfaces, for which prompts, and how often. Build prompt test suites (10–15 query variations per topic), run them on a regular cadence, and log the results. Without dedicated tooling it becomes manual fast, which is why monitoring platforms exist.
Should I create separate pages for SEO vs AI answers, or can one page do both?
One page can do both, and most of the time it should. The overlap is big: clean structure, clear entities, strong evidence, and technical accessibility help in both systems. What grounding adds is passage-level craft, individual sections that can stand alone as quotable answers. You don’t need parallel content; you need pages that are both rankable and citable.
The new content strategy is indexable + citable + measurable
Indexing makes you retrievable. Grounding makes you quotable. In 2026, you need both. Run the Grounding Readiness Checklist on your priority pages, then put the five-area measurement framework in place so you’re watching both layers. Check citations weekly, not once a quarter. Teams that understand Bing AI grounding vs search indexing early will capture the answer layer while everyone else is still fighting over blue-link rankings.
Track grounded AI citations alongside search rankings. Start with Vizup’s Watcher Agent.