Agentic Resource Discovery (ARD) is an emerging open specification that aims to give the web a machine-readable directory layer, so AI agents can locate, understand, and verify the tools, services, and knowledge a site publishes. The simplest way to picture it is as a structured set of listings that tells an agent where to find a capability, whether that is an API endpoint, a booking flow, or a knowledge base.
For years, digital teams have tuned sites for human readers and search crawlers. Now a different kind of visitor is showing up: autonomous AI agents that are less interested in browsing pages than in completing tasks. They query, evaluate, and act. Automated internet traffic from AI agents and agentic browsers grew by 7,851% year-over-year in 2025, according to HUMAN Security's 2026 State of AI Traffic & Cyberthreat Benchmark Report. That makes ARD less of a thought experiment and more of a positioning question: if agents become a meaningful discovery and transaction channel, you want your capabilities to be legible to them. Gartner predicts that up to 40% of enterprise applications will include integrated task-specific AI agents by 2026, up from less than 5% in 2025.
What Problem Does ARD Actually Solve?
The web still assumes a human in the loop. A person can land on a restaurant homepage, skim the menu, spot the reservation widget, and book a table. An AI agent trying to do the same runs into messy realities: unstructured HTML, navigation that implies meaning without stating it, and no dependable way to confirm which services actually exist on that domain. Without a shared standard, agents end up guessing, scraping, or leaning on incomplete heuristics, which is where errors, hallucinations, and failed tasks creep in.
ARD's bet is straightforward: give sites a common way to declare what they can do. Rather than forcing an agent to infer from marketing copy that a site offers flight booking, an ARD catalog can say it plainly: "here is my booking API, here is my knowledge base, here are my supported protocols." That shift turns scattered web resources into something agents can query and act on, which is why people frame it as a building block for an "agent discovery" layer. As discovery has fundamentally changed, moving from human-interpreted pages to agent-queried catalogs looks like the next structural step.
How Agentic Resource Discovery Works: The Nuts and Bolts
ARD is not a single file you drop on a server and forget. It is a framework with two main pieces: a static manifest format that publishers host on their own domains, and a dynamic registry API that supports live, intent-based search (Hugging Face, 2026). Together, they form a distributed network of resources that agents can query without having to reverse-engineer each site. The ARD specification is still a draft open standard, with contributors listed from Microsoft, Google, GoDaddy, Hugging Face, and others.
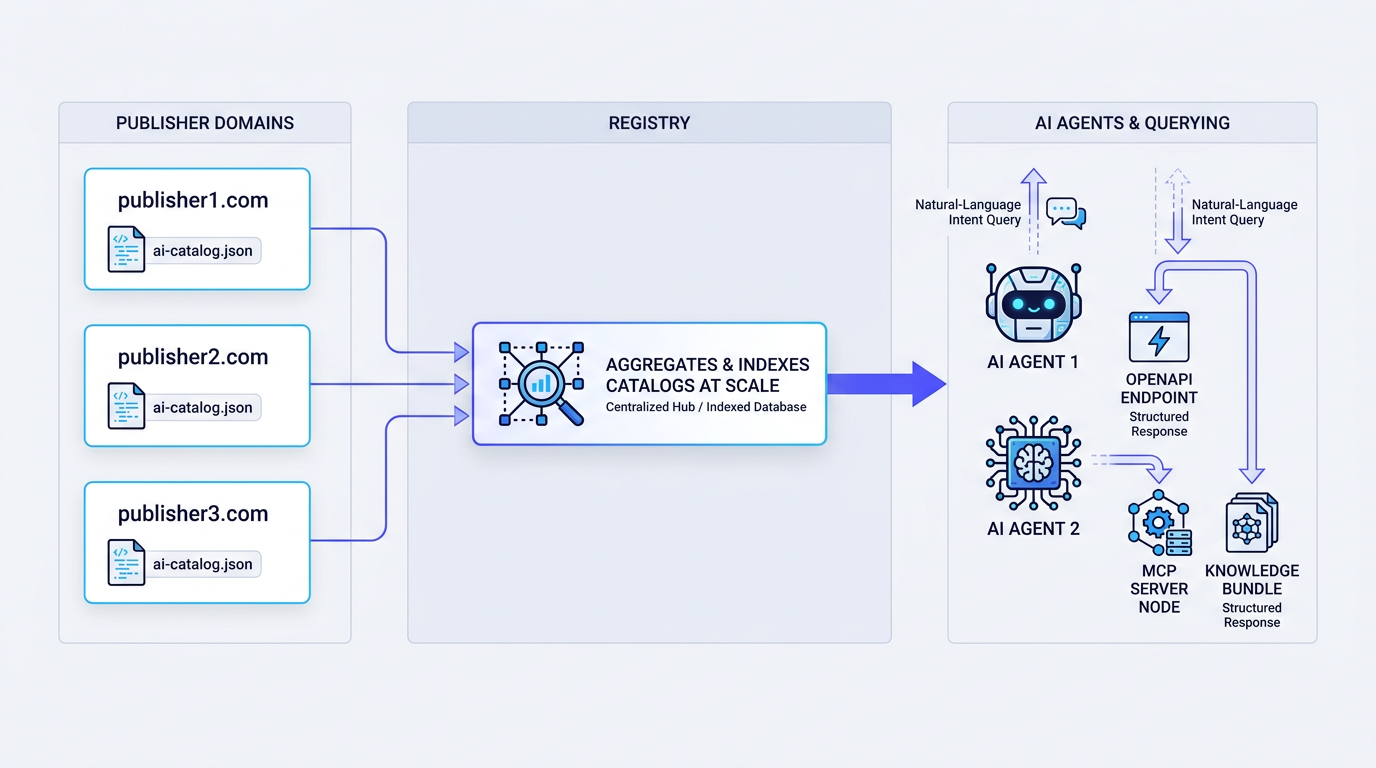
ARD's three-layer architecture connects publisher catalogs to registries that AI agents query by intent.
The AI Agent Catalog: Your Site's Manifest
The entry point is a site-hosted manifest, typically named ai-catalog.json, that enumerates the resources you want agents to find. Each entry points to a concrete capability: an OpenAPI spec for a REST tool, an MCP server for agent-to-agent communication, a knowledge bundle (such as an OKF file), or even a nested catalog for a large organization. The catalog is not the resource itself; it is a set of structured pointers plus metadata describing what the resource does, which protocols it supports, and who published it. If you are already thinking about making your website AI agent-friendly, this catalog is the artifact that makes those capabilities explicit instead of implied.
Registries: Enabling MCP A2A Discovery at Scale
A catalog helps most when an agent already knows your domain. Discovery gets harder when the agent starts with an intent and no brand in mind. That is the job of registries: third-party services that crawl for ARD catalogs, index them, and expose a query API. An agent can ask something like "find an agent that can book flights from SFO to JFK" and receive a ranked set of matching resources. This is the piece that turns isolated catalogs into a searchable network and enables MCP A2A discovery beyond a single known site. One important boundary: ARD is a discovery protocol, not an execution runtime (AgenticResourceDiscovery.org, 2026). After the agent finds the right resource through a registry, it still invokes that resource via its native protocol, whether that is MCP, A2A, or a standard REST API.
Trust and Verification
Discovery without trust quickly becomes a liability. If any site can claim any capability, agents are easy targets for spoofing and manipulation. The ARD specification describes mechanisms for verifiable credentials and trust metadata so an agent can check that a resource is published by who it claims to be. For a machine-readable web where agents act autonomously on a user's behalf, that verification layer is not optional.
What ARD Is NOT: Clearing Up Misconceptions
Because ARD is early, the story around it is already getting fuzzy. Three points are worth setting straight.
It's not a replacement for SEO. ARD is aimed at agents; SEO is aimed at human-facing search engines. The two can run in parallel. Your human audience still matters, and traditional search optimization is not going away. Understanding AI search visibility means planning for both discovery paths to coexist.
It's not the content itself. ARD is the pointer ("where to look"). Formats like OKF or your API documentation are the content ("what to read or use"). They fit together cleanly: ARD can tell an agent that a knowledge bundle exists at a URL, and OKF (or another format) provides the structured information once the agent arrives.
Note: Info: Provenance note: While Google is listed among ARD's contributors alongside Microsoft, Hugging Face, and GoDaddy, current references describe ARD as a multi-stakeholder open specification, not a single company's product. Treating it as "a Google thing" overstates what is confirmed. The spec is hosted at AgenticResourceDiscovery.org and remains in draft status as of mid-2026.
How to Prepare Your Digital Presence for the Agentic Web
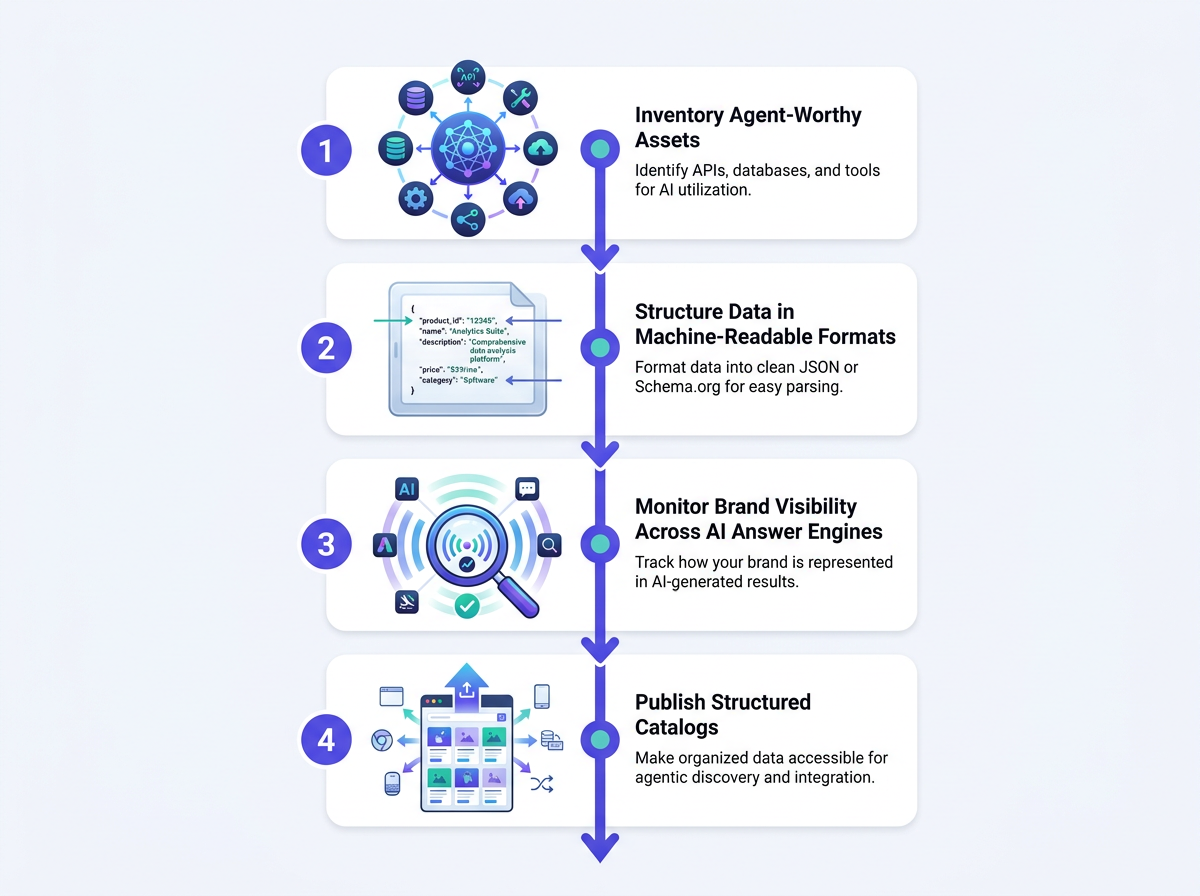
Preparing for ARD starts with auditing your digital assets and structuring them for agent consumption.
You do not have to wait for the ARD spec to be finalized to do useful work. Most of the prep is the kind of operational cleanup that helps today and leaves you better positioned if ARD solidifies into a default.
Inventory your agent-worthy assets. Walk your own properties and list what an autonomous agent would actually want to use: APIs, calculators, product databases, booking tools, structured knowledge bases. If you understand what an SEO agent is, this will feel familiar: these are the same underlying resources an SEO agent would look for when judging your site's usefulness.
Structure your key information now. Even before ai-catalog.json is widely adopted, machine-readable fundamentals pay off: clean APIs, well-documented endpoints, and structured content that does not rely on a human to interpret it. That helps current search engines and sets you up for agent protocols later. Tools like Lighthouse's agentic browsing audits can give you a concrete read on readiness.
Monitor how your brand appears across AI channels. AI answer engines are already functioning as a preview of agentic discovery. If those systems surface inaccurate or incomplete information about your brand now, a future catalog will not fix the underlying visibility problem. This is where a platform like Vizup fits. Vizup helps brands monitor, create, optimize, and publish across Search, Social, Communities, AI Answer Engines, and Local Discovery using a combination of AI agents, human experts, and live SEO, AEO, and GEO tools. The workflow is organic-first and built for multi-channel visibility; paid ads are positioned as amplification, not the default lever.
Key Takeaways
- Agentic Resource Discovery (ARD) is a draft open specification describing how AI agents can discover and verify tools, services, and knowledge on the web. Contributors listed include Microsoft, Google, Hugging Face, and GoDaddy.
- ARD relies on site-published AI agent catalogs (
ai-catalog.json) that registries crawl and index, creating a distributed discovery layer agents can search by intent. - ARD is the "where to look" layer: it points to resources that are executed or consumed via their own protocols (OpenAPI, MCP, A2A). It is a discovery protocol, not an execution runtime.
- ARD pairs naturally with content formats like OKF: ARD provides the pointer, and OKF (or an API spec) provides the structured material at the destination.
- You can prepare without waiting for the spec to settle by inventorying digital assets, making key data machine-readable, and tracking brand visibility across AI answer engines with tools like Vizup.
- ARD does not replace SEO. It adds a parallel channel aimed at autonomous agents, which appear to be a growing share of web traffic.
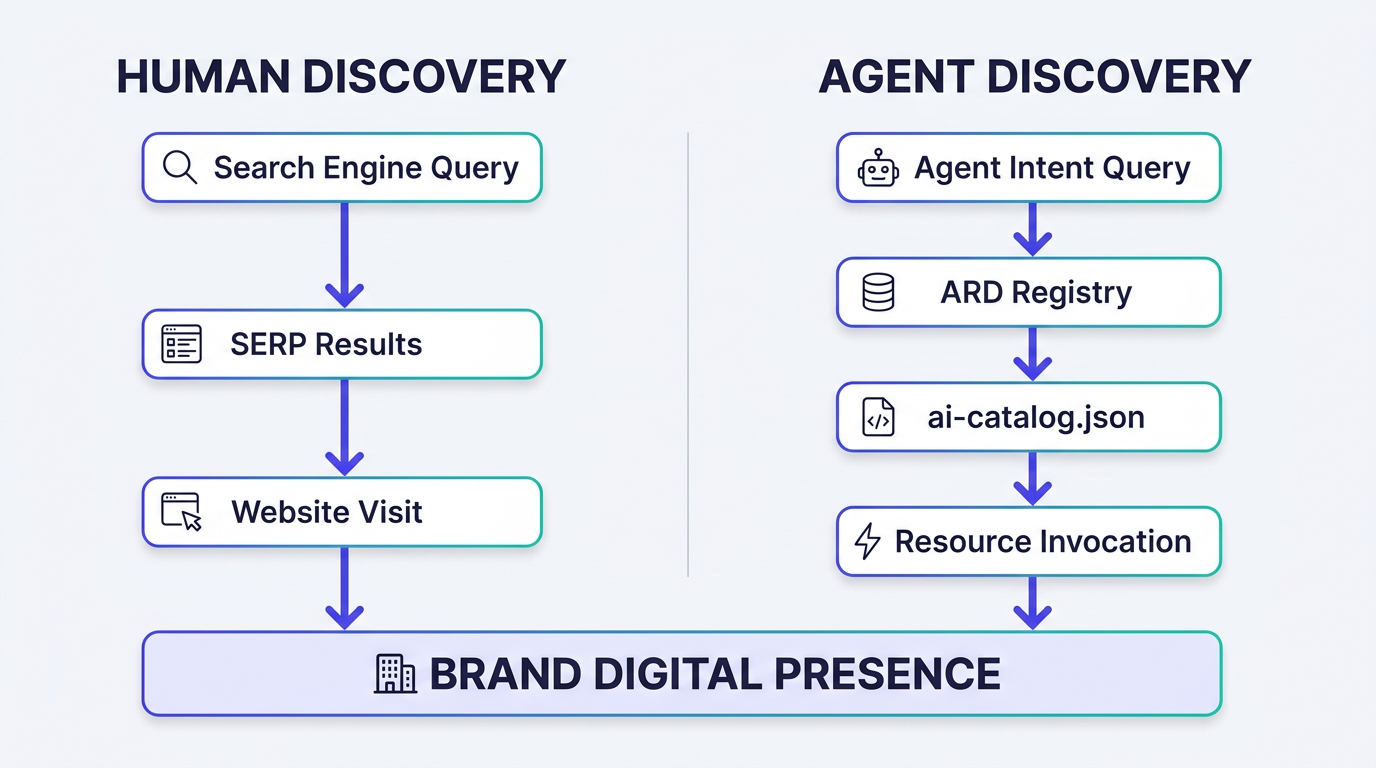
SEO and ARD run in parallel — both channels stem from the same brand digital presence.
Frequently Asked Questions
Is Agentic Resource Discovery (ARD) a Google product?
No. Google is listed among ARD's contributors, but the spec is presented as a multi-stakeholder effort that also includes Microsoft, Hugging Face, GoDaddy, and others. It is hosted at AgenticResourceDiscovery.org as an open draft specification. Based on current references, pinning it on a single company is not supported.
What's the difference between ARD and Schema.org markup?
Schema.org helps search engines interpret what a page is about (a recipe, a product, an event). ARD is about what a site can do, listing actionable capabilities like APIs, tools, and agent endpoints. In practice, Schema.org annotates content for human-facing search, while ARD catalogs resources for autonomous agent use. They operate at different layers and can coexist.
Do I need to create an ai-catalog.json file for my website today?
Not necessarily. The ARD specification is still in draft status and the format may change. You can still get ahead by inventorying agent-worthy assets, keeping data machine-readable, and making sure APIs are well documented. Those steps help now and make it easier to adopt ARD quickly if and when it stabilizes.
How does ARD relate to the Open Knowledge Format (OKF)?
ARD is the directory layer ("where to look"), while OKF is a content format ("what to read"). An ARD catalog entry can point to an OKF knowledge bundle at a specific URL, so an agent can discover the resource via ARD and then consume the structured knowledge via OKF. They are meant to compose cleanly.
Will ARD replace traditional SEO?
No. ARD targets AI agents; SEO targets human users via search engines. Expect them to run in parallel. The practical move is to track visibility across search, AI answer engines, and emerging agent channels. A platform like Vizup helps you monitor and optimize across these surfaces with a single organic-first workflow.