The Open Knowledge Format (OKF) is a vendor-neutral, open specification from Google Cloud for packaging organizational knowledge (datasets, metrics, APIs, runbooks) as a directory of markdown files with YAML frontmatter. The result is a cross-linked graph an AI agent can read, reason over, and act on. Introduced in June 2026 as OKF v0.1, the format puts a name and a structure on what many teams have already built informally: an LLM wiki.
Most companies' institutional brain is smeared across Notion pages, Confluence spaces, Google Docs, and proprietary catalogs. Each new agent you roll out ends up rebuilding the same context layer: what the canonical metric definition is, which endpoint is deprecated, which runbook applies in the EU. Google is pitching OKF as a single portable structure for that knowledge, aimed less at human browsing and more at the agents teams are starting to rely on. Here's a practical look at how OKF is put together, what Google actually shipped, and how to decide if it's worth adopting.
Why AI Agents Need a Special Diet
AI agents can execute tasks, but they're notoriously bad at "just knowing" how your organization works. They don't come with the institutional memory a tenured employee has: which metric definition is canonical, which API endpoint is deprecated, which runbook applies to the EU region. Meanwhile, the knowledge they need lives in unstructured docs or locked inside proprietary systems, so every agent ends up with bespoke plumbing to fetch the right context. If you want a concrete example, what an SEO agent is makes the limitation obvious: even a strong agent is capped by the knowledge it can reliably access.
And the tax shows up over and over. A data team builds a connector for one agent; a support team builds another for a different agent; nobody wants to maintain any of it. OKF's pitch is to pay that cost once: give producers a shared format and give consumers a predictable structure. In the spec's language, it's the agent context standard pattern: write knowledge once, let any agent consume it.
How the Open Knowledge Format Actually Works
OKF is not a platform or a SaaS product. It is a set of conventions for organizing files you probably already have. The building blocks are intentionally plain: directories, markdown files, and YAML frontmatter. If you have seen the LLM wiki pattern, this is the standardized version: maintain interlinked markdown that an agent can read and update, as detailed in the official spec on GitHub.
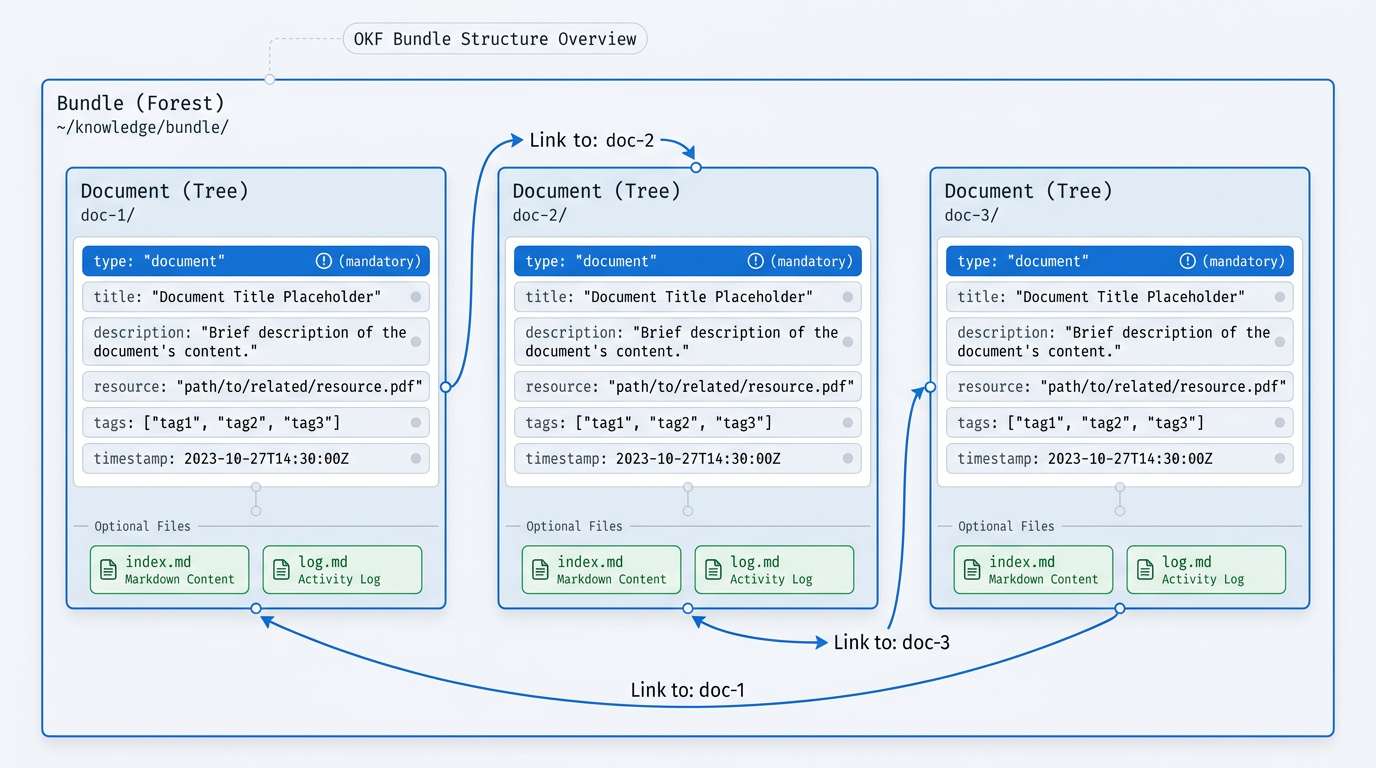
The Anatomy of an OKF Bundle
In OKF, a single concept (a specific dataset, a metric definition, an API endpoint) becomes a document, which Google calls a "tree." Each tree is a directory with a primary markdown file plus any related assets. Group a set of related documents together and you have a bundle, or "forest." Documents connect to each other using standard markdown links, which is enough to produce a navigable knowledge graph without proprietary tooling.
The YAML frontmatter is intentionally sparse. Only one field is mandatory: type. Reserved (but optional) fields include title, description, resource, tags, and timestamp. Two optional files fill in the practical edges: index.md for progressive disclosure (summaries that help agents decide whether to read deeper) and log.md for change history. The official spec on GitHub is explicit that this minimalism is a feature, not an omission.
Three Design Principles Worth Noting
- Minimally opinionated. With only
typerequired, the on-ramp is basically "make a markdown file." Teams can start from whatever documentation they already have. - Producer/consumer independence. The team writing the knowledge doesn't need to predict which agent will consume it, and the agent doesn't need to care who authored it. That decoupling is what gives OKF its portability.
- Format, not platform. There's no proprietary SDK to read or write OKF. Any text editor, any CI pipeline, and any agent framework that can handle files can work with it.
What Google Shipped for v0.1
Google is careful to frame v0.1 as "a starting point, not a finished standard." The goal is to pull in feedback, not to declare OKF the one true way to do knowledge management. Still, this isn't just a PDF spec: Google shipped working code alongside it.
The reference producer is a BigQuery enrichment agent that generates OKF documentation for datasets by turning schema metadata into structured markdown. The reference consumer is a static HTML visualizer that renders an OKF bundle as a browsable site, which is handy for human review and debugging. Google also published sample bundles on GitHub. For Google Cloud customers, the most immediate hook is the Knowledge Catalog OKF integration: Knowledge Catalog can ingest OKF bundles directly, which gives data teams a concrete reason to start producing them now.
Info: Google has framed OKF as an agent-knowledge and data-sharing format, not as an SEO ranking tactic. Whether it matters outside Google Cloud depends on what the broader community does with it.
Where OKF Fits with llms.txt and ARD
The first reaction from many teams will be: "Great, another standard." The useful way to read this, though, is that OKF, llms.txt, and ARD (Agentic Resource Discovery) target different layers and can stack together. Google's testing of bot authentication is relevant context, because none of these formats matter if you can't control agent access in the first place.
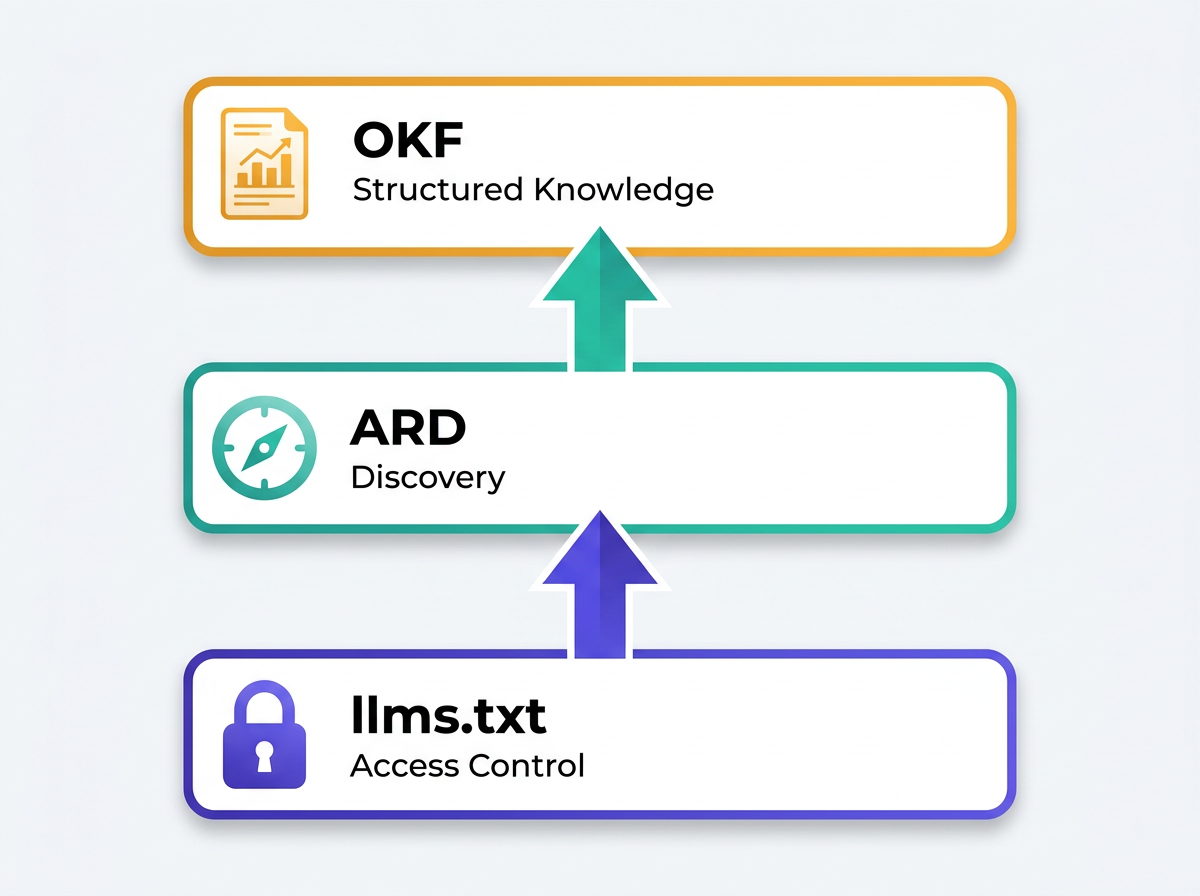
Practically speaking, llms.txt handles permissioning, ARD helps discovery, and OKF defines the structure of the knowledge base itself. Teams working on agent readiness should treat these as components of a single posture, not mutually exclusive bets.
Why OKF Matters for Brand Visibility
An Open Knowledge Format is not a shortcut to rankings, but it reflects a larger shift: AI systems increasingly need structured, reliable context before they can mention, recommend, or act on behalf of a brand. Vizup helps teams close that gap by monitoring how their brand appears across search, AI answer engines, communities, and emerging agentic discovery surfaces. Request a demo to see how Vizup's AI agents can optimize your visibility.
Should Your Team Adopt OKF in 2026?
Adopting OKF now is a bet that agentic workflows will move from experiments to core operations. It pays off fastest in organizations with messy, siloed knowledge: large product catalogs, internal data dictionaries, sprawling support documentation, or metric definitions spread across multiple teams. If your knowledge already lives in markdown (common in engineering orgs), the migration cost is modest. If it's trapped in Confluence or Notion, expect an export-and-restructure step before OKF feels natural.
The sober take is that OKF is early and broader adoption is still unproven. But OKF's simplicity is also what makes it a low-risk move: you're not buying into a vendor ecosystem, you're organizing files. Even if the spec shifts, a directory of markdown doesn't become a liability overnight.

One more consideration: structure alone isn't the finish line. OKF helps you package knowledge so agents can use it; you still need to track whether that knowledge is actually performing across search, AI answer engines, and communities. Vizup's Organic Autopilot is positioned around that loop: monitoring, creating, optimizing, and publishing content across Search, Social, Communities, AI Answer Engines, and Local Discovery, using AI agents, human experts, and live SEO, AEO, and GEO tools. If you're publishing structured content at scale, staying current on Google's spam policies for generative AI matters just as much as the format you pick.
Key Takeaways
- The Open Knowledge Format is a vendor-neutral spec for structuring organizational knowledge as markdown files with YAML frontmatter, built for AI agents.
- Each concept needs only one required field (
type), which keeps the barrier to entry low. - OKF standardizes the LLM wiki pattern: documents are "trees," bundles are "forests," and markdown links create a knowledge graph.
- Google shipped reference implementations (a BigQuery agent and an HTML visualizer) plus Knowledge Catalog ingestion, while framing v0.1 as a starting point.
- OKF complements llms.txt (access) and ARD (discovery) rather than replacing them.
- The downside risk is small (it's just files), but long-term traction depends on adoption beyond Google Cloud.
Frequently Asked Questions
Is Google's Open Knowledge Format (OKF) a ranking factor for SEO?
No. Google has been explicit that OKF is meant for AI agents, not as a search-ranking signal. It doesn't change how Google Search ranks pages. The point is to make organizational knowledge easier for agentic systems to consume, not to tune traditional SEO.
What's the difference between OKF and a regular company wiki on Notion or Confluence?
Notion and Confluence are platforms: proprietary formatting, built-in access controls, and their own rendering and APIs. OKF is a portable format: plain markdown in directories, with no vendor dependency. Any tool or agent that can read text files can consume OKF, and you don't need a license, an API key, or a specific platform to use it.
Do I need to be a programmer to create OKF markdown files?
No. If you can write markdown and add a few lines of YAML at the top (with 'type' as the only required field), you can create OKF documents. The spec stays simple on purpose so content and knowledge teams can contribute, not just engineers.
Can I use the Open Knowledge Format with AI models other than Google's?
Yes. OKF is vendor-neutral by design. It's standard markdown plus YAML, which any LLM or agent framework can parse. There's no Google-specific SDK or dependency, so it can work with OpenAI, Anthropic, open-source models, or any system that reads text.
How does OKF relate to knowledge graphs and schema markup?
Schema markup (like Schema.org) targets web pages and search engines. OKF targets internal and organizational knowledge meant to be consumed by AI agents. Different audiences, different use cases. That said, OKF bundles do form a knowledge graph in practice because the markdown links connect concepts into a navigable network.