
Somewhere right now, a buyer is asking ChatGPT which tool to pick in your category. Perplexity is handing someone a shortlist they'll trust without ever opening a traditional results page. Gemini is condensing your competitors' pitch into a few neat bullet points for a procurement manager doing diligence. AI is already shaping how people find and judge brands, and the only real question is whether you can see what it's saying about yours.
If you're not measuring your AI brand presence yet, you're flying blind. This piece lays out seven concrete steps to get from zero visibility into how LLMs portray your brand to a monitoring loop you can run repeatedly, so issues show up in your data before they show up in lost deals.
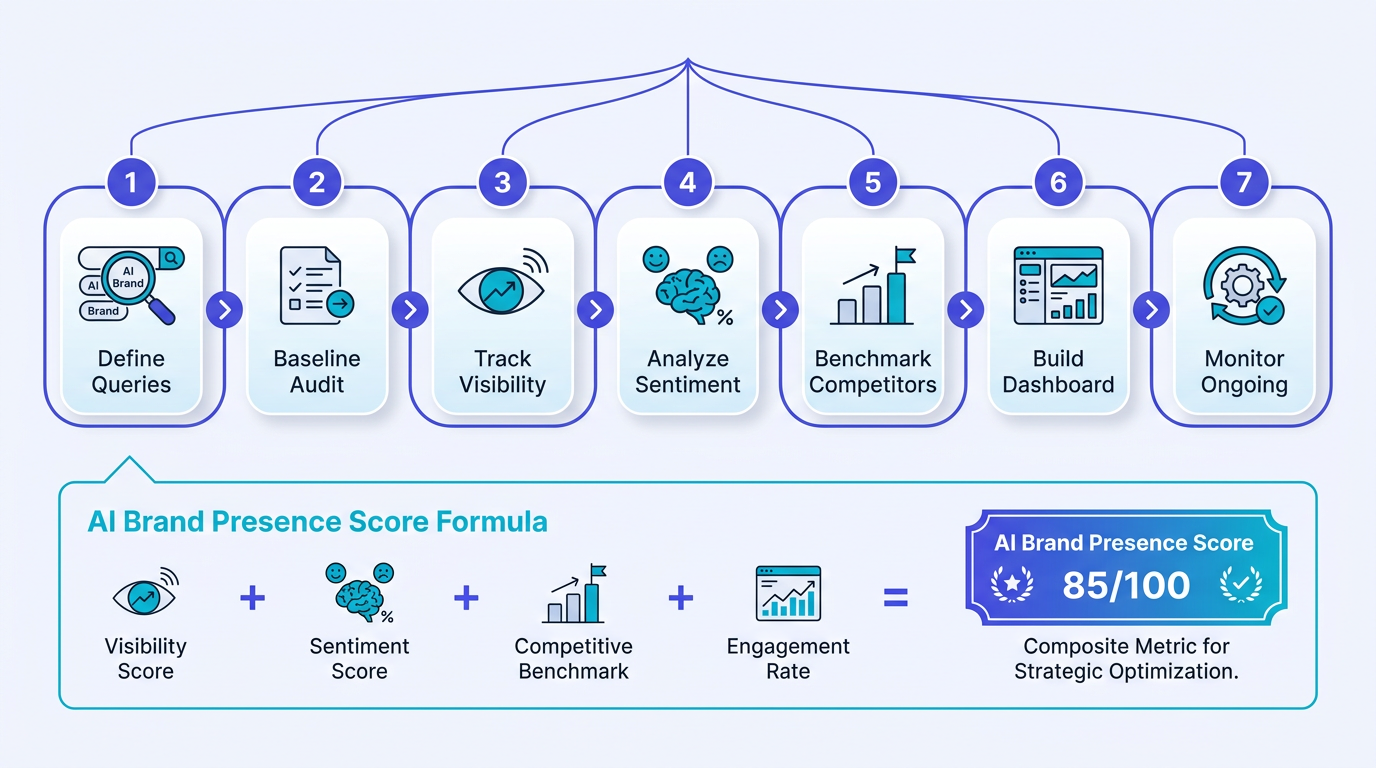
Info: The 7 steps at a glance: 1) Define your brand entities and queries, 2) Run a baseline LLM presence audit, 3) Track AI brand visibility across models, 4) Analyze sentiment and accuracy, 5) Benchmark against competitors, 6) Build a scoring dashboard, 7) Set a recurring monitoring cadence.
What You'll Need Before You Start
You can get a first read without spending much. The free tiers of ChatGPT, Gemini, and Perplexity are enough to run an initial audit. The non-negotiable is coverage across at least three models: checking just one gives you a comforting story that can be wildly incomplete, and Step 3 explains why.
Before running your first query, have these ready:
- Access to ChatGPT, Gemini, and Perplexity (free tiers work for initial audits)
- A monitoring tool like Vizup for automated, consistent querying across models
- A spreadsheet or Looker Studio dashboard for logging results over time
- A list of your core brand terms, product names, and the questions your buyers actually ask before making a purchase decision
Most teams skimp on the query list and pay for it later. Give it a focused 30 minutes before you open any chatbot. Sloppy prompts create noisy, misleading outputs, and then you burn hours chasing problems that are really just bad inputs.
Step 1: Define Your Brand Entities and Target Queries
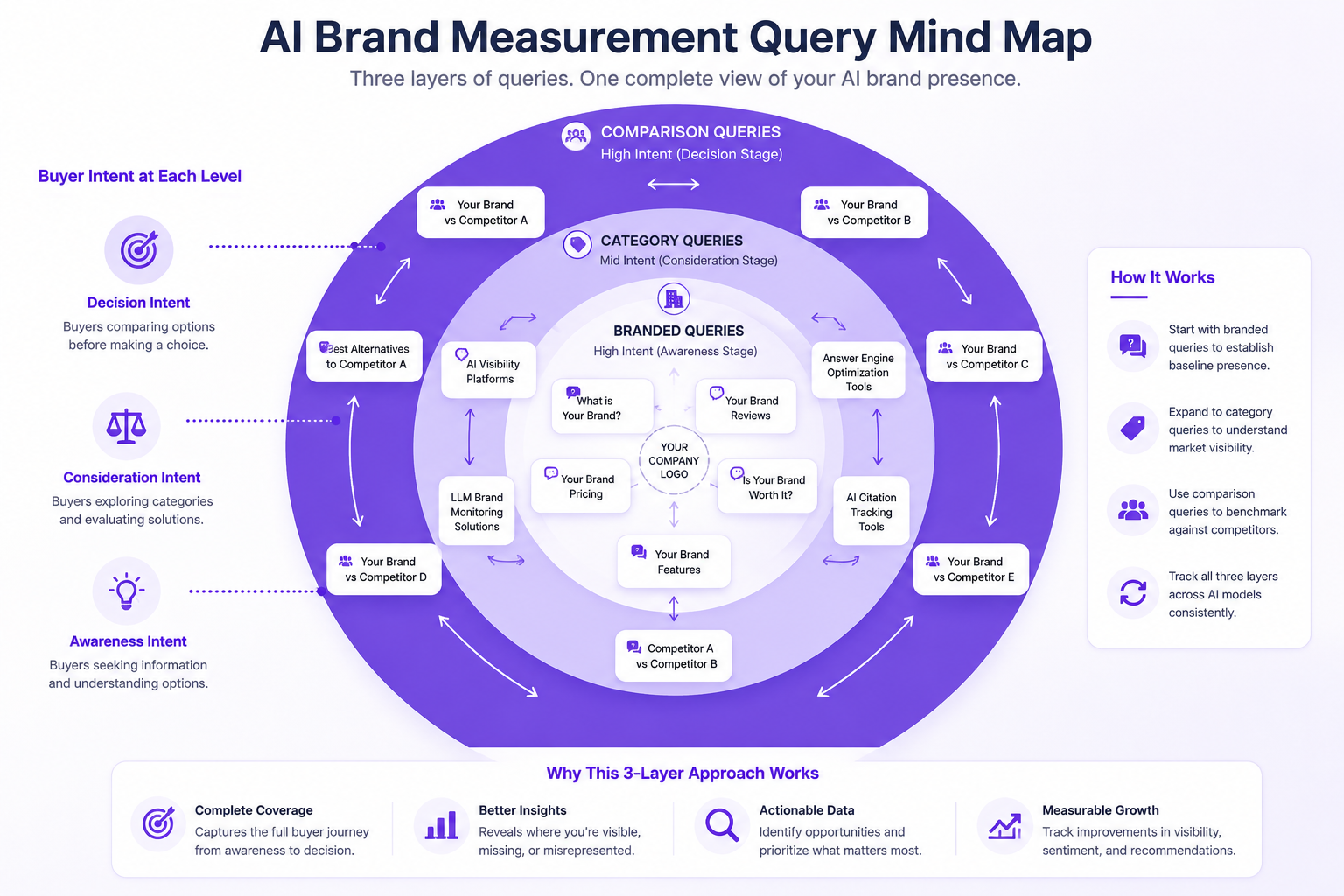
Build your prompts in three layers. Branded queries name you outright ("What is [your brand]?" or "Is [your brand] worth it?"). Category queries mirror how people shop before they know you exist ("best tools for answer engine optimization" or "how do I monitor my brand in AI search"). Comparison queries are where the stakes jump: "[Your brand] vs [competitor]" or "alternatives to [competitor]."
Aim for 20 to 30 queries spread across all three layers. A common failure mode is over-indexing on branded prompts and then celebrating the obvious result: the model knows your name. The more revealing data lives in category and comparison prompts, because that's where undecided buyers actually are.
Tip: Quality check: For every query you write, ask yourself: "Would a real buyer type this into an AI chatbot?" If it sounds like something a marketer wrote, rewrite it in plain language.
Step 2: Run a Baseline LLM Presence Audit
An LLM presence audit is the unglamorous part: you ask your target prompts, model by model, and capture exactly how your brand shows up (or doesn't). Everything else you do depends on having that baseline.
The manual version is straightforward. Paste each query into ChatGPT, Gemini, and Perplexity, screenshot the response, and log the outcome in a spreadsheet. With 30 queries across three models, that's 90 separate interactions. You can muscle through it once. As a recurring process, it collapses under its own weight, especially because outputs shift constantly.
Vizup's Answer Engine Monitoring runs the same query set across models in parallel and captures structured results you can trend over time. The real problem with manual audits isn't just tedium; it's consistency. If you run ChatGPT on Tuesday and get around to Gemini two weeks later, you're no longer measuring the same moment in time. That gap alone is enough to make your baseline data unreliable.
Step 3: Track AI Brand Visibility Measurement Across Models
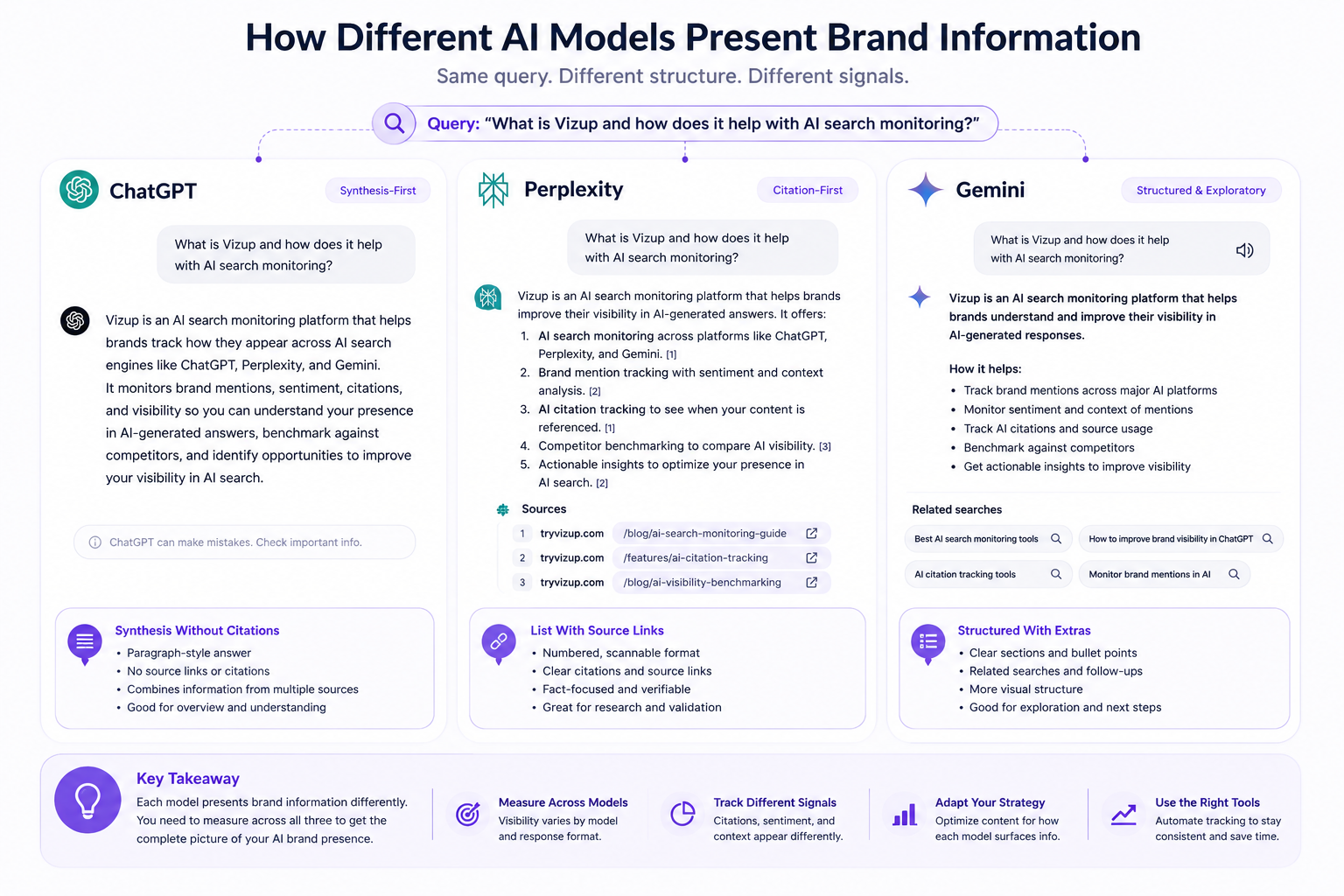
Each model has its own quirks, and those quirks change what "visibility" even means. Perplexity leans on citations and links, so source coverage and citation frequency matter most there. ChatGPT often produces polished synthesis without attribution, which means your content might be shaping the answer even when your name barely appears. Gemini tends to reflect Google's index more directly than the other two, so it often tracks closer to your organic search footprint.
For every query in every model, capture four fields: binary presence (mentioned or not), placement in the response (top pick, mid-list, footnote), context (recommended, neutral, or flagged as a concern), and whether the model includes a citation or link to your site. That last field is easy to misread. A meaningful portion of AI brand presence comes from what you could call indirect influence, where the model draws on your content to shape an answer without naming you directly. If you only count explicit mentions, you'll miss a real slice of what's actually happening. Vizup's AI citation tracking captures both direct and indirect presence, which gives you a far more complete picture than manual logging ever will.
Step 4: Analyze Sentiment and Accuracy
A mention is not a win. If the model gets you wrong while naming you, that can do more damage than being left out entirely.
Label each mention as one of four outcomes: positive (recommended, praised, framed as a top choice), neutral (listed with no real judgment), negative (flagged for limitations or warned against), or factually incorrect (wrong pricing, outdated features, mixed up with a competitor). The last bucket is where things get expensive. Brands get saddled with a competitor's pricing, credited for features they killed two years ago, or pushed into the wrong market segment. LLMs will confidently fill gaps with plausible guesses, and buyers rarely stop to verify.
Warning: Watch for this: Factual errors in AI responses often reveal gaps in your own public-facing content. If an LLM is getting your pricing wrong, it's probably because you haven't published clear, crawlable pricing information that models can reference. Fix the source, not just the symptom.
Step 5: Benchmark Against Competitors
Run the same query set against three to five competitors and compare share-of-voice across AI responses. The goal isn't to obsess over what competitors are doing. It's to understand where you stand in the market narrative that AI models are constructing, and to identify the specific gaps in your own visibility, accuracy, and recommendation rate that are worth closing. Competitor data is context. Your brand's performance is the point.
| Brand | Mention Rate % | Avg Sentiment Score | Factual Accuracy % | Citation Frequency | Composite AI Score | Primary LLM Strength |
|---|---|---|---|---|---|---|
| Your Brand | 62% | 3.4/5 | 78% | Medium | 68/100 | Perplexity |
| Competitor A | 81% | 4.1/5 | 91% | High | 84/100 | ChatGPT + Gemini |
| Competitor B | 44% | 3.8/5 | 85% | Low | 57/100 | Gemini |
| Competitor C | 73% | 2.9/5 | 69% | High | 61/100 | Perplexity |
| Competitor D | 38% | 4.3/5 | 94% | Medium | 55/100 | ChatGPT |
| Illustrative scorecard. Your actual numbers will vary by query set and audit date. Track trends, not snapshots. |
Read the table as a diagnostic for your own position, not a leaderboard. A competitor with a high mention rate but poor accuracy (like Competitor C in the sample) signals something useful: buyers who follow up on those AI recommendations are hitting friction. Your opening is to be the brand the models describe cleanly and correctly, with accurate pricing, current features, and consistent framing across all three platforms. That's a competitive advantage you can actually build toward. Vizup's AI search performance tracking makes it straightforward to run this kind of structured benchmarking on a regular cadence, so you're always working from current data rather than a stale snapshot.
Step 6: Build a Scoring Dashboard to Measure Your AI Brand Presence Over Time
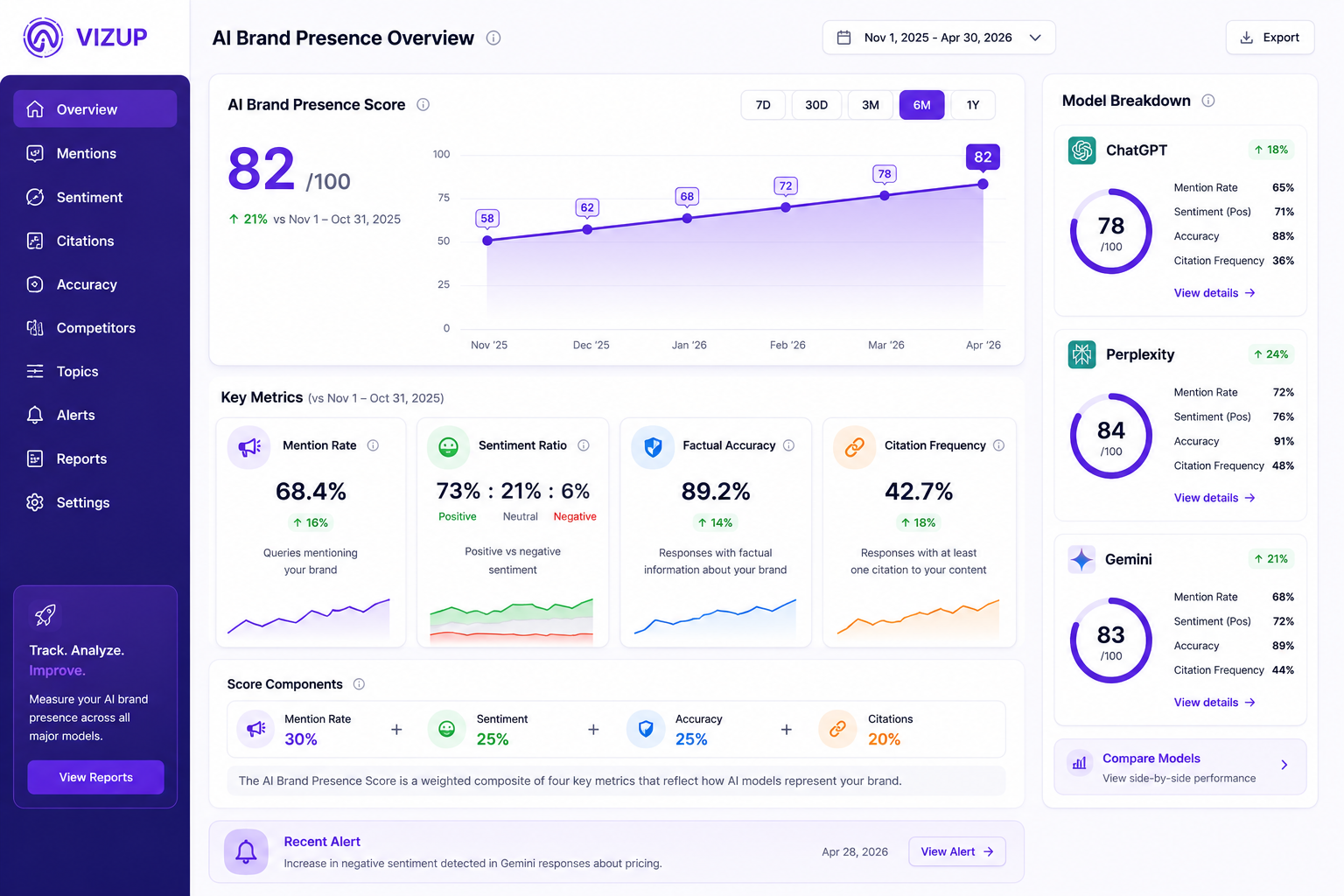
Turn the audit into a single composite AI Brand Presence Score built from four inputs: mention rate (about 30% weight), sentiment ratio (25%), factual accuracy rate (30%), and citation frequency (15%). The exact weights are less precious than the discipline of choosing a system and keeping it stable, so the score means the same thing next month as it does today.
Vizup's AI visibility platform handles the math automatically and surfaces trend lines across all four inputs in a single dashboard view. If you're rolling your own, a weighted-average formula in Google Sheets is a reasonable starting point. Either way, the number is only useful in motion. A 68 that has climbed for three straight months is a healthier signal than a 75 that hasn't budged.
Step 7: Set a Recurring Monitoring Cadence
LLM outputs don't sit still. Models retrain, change their knowledge cutoffs, and reshuffle recommendations as new sources get indexed. A brand that showed up reliably in February can vanish by April without any alert, and without any obvious change on your end.
A workable cadence looks like this: weekly spot-checks on your 10 highest-priority queries (the ones tied to active buying decisions), plus a full audit every month. With a tool like Vizup, the weekly checks are a 15 to 20 minute habit. The monthly run is where you refresh competitor benchmarks and recompute the composite score.
If you catch a drop, the follow-on work is AEO (Answer Engine Optimization). The practical version is straightforward: the gaps you surfaced in the audit become your optimization to-do list. The Complete Guide to Improving Brand Visibility in AI Search goes deep on that side of the work.
Common Mistakes That Will Waste Your Time
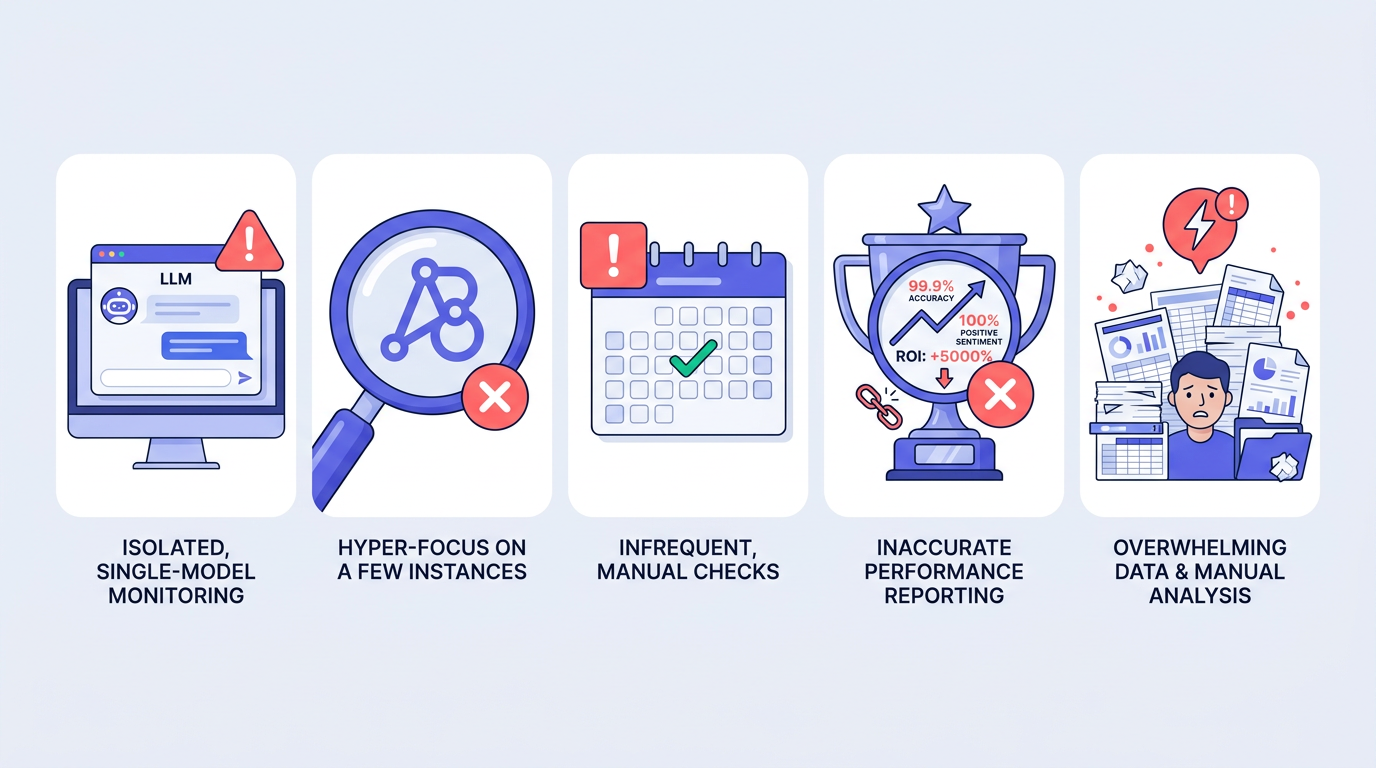
Querying only one LLM. ChatGPT and Perplexity can answer the same question in completely different ways. Building a measurement strategy off a single model is like running a brand survey in one city and calling it national. You'll get a partial picture and make decisions based on it.
Using only branded queries. Ask "What is [your brand]?" and you'll usually get something flattering. That's not the point. The real signal is in category and comparison prompts, where buyers are still deciding and the models are steering them toward or away from you.
Running a one-time audit. AI brand presence is not a screenshot you can file away. It moves. Teams that run one audit, celebrate or panic, and never return are measuring a moment that has already passed.
Prioritizing vanity mentions over accuracy. A high mention rate paired with wrong details is not "awareness." It's a support ticket waiting to happen. When buyers act on bad AI-generated information and hit friction, they blame you, not the model.
Trying to do everything manually at scale. Manual querying is fine for a baseline. As a monitoring system, it breaks quickly. Teams can sink 10 or more hours a week into copy-pasting prompts when the same answer engine monitoring coverage takes about 20 minutes with the right tool. If you're sorting out your stack, that guide to AI brand visibility optimization tools is a useful read before you lock in a workflow.
Summary and Next Steps
You now have a loop you can actually run: define query layers, capture a baseline, track visibility model by model, grade sentiment and accuracy, benchmark competitors, roll it into a score, and keep it on a cadence. That's the workflow.
Next comes the part that changes outcomes: using what you found to drive an AEO strategy that improves how LLMs describe you. Measurement without follow-through is just a spreadsheet. But optimization without measurement is guessing, and most brands are still guessing.
Vizup's free monitoring tier lets you run your first LLM presence audit in under 10 minutes. You'll see exactly where your brand appears across ChatGPT, Perplexity, and Gemini, how it's described, where the factual gaps are, and how you stack up against competitors in your category. The AI brand visibility data you collect in that first session is enough to build a real measurement baseline and start closing the gaps that matter. Head to tryvizup.com and run your first audit before a competitor sets the narrative for you.
Frequently Asked Questions
What metrics should I track when measuring AI brand presence?
The four core metrics are mention rate (how often your brand appears across AI responses to relevant queries), sentiment (whether those mentions are positive, neutral, or negative), factual accuracy (whether the model's description of your brand is correct), and citation frequency (how often the model links to or attributes your content). Together, these feed into a composite AI Brand Presence Score that gives you a single trendable number. Share of voice, which compares your mention rate against competitors across the same query set, is a useful fifth metric once you have a baseline. Vizup tracks all of these automatically across ChatGPT, Perplexity, and Gemini.
How often should I measure my AI brand presence?
Weekly spot-checks on your top 10 priority queries, plus a full audit each month. Outputs change as models retrain and update, so monthly is the floor if you want to catch meaningful shifts. In especially competitive categories, or when you're actively running AEO work, weekly full audits can be worth it. Tools like Vizup keep the process from taking over your calendar.
What's the difference between AI brand visibility measurement and traditional SEO tracking?
Traditional SEO tracking is built around search results pages: rankings, click-through rates, and organic traffic from Google and Bing. AI brand visibility measurement is about how (and whether) you show up inside AI-generated answers from ChatGPT, Perplexity, and Gemini. The mechanics don't map cleanly: there are no stable rank positions, and the signals aren't classic crawl-and-index metrics. Instead, you track mention rate, sentiment, factual accuracy, and citation frequency. The complete guide to AI search monitoring explains how the two approaches fit together.
Can I measure my AI brand presence for free without any tools?
Yes, if you're doing a one-time baseline. Run your query list through the free tiers of ChatGPT, Gemini, and Perplexity, then log the outputs in a spreadsheet. With 20 to 30 queries across three models, plan on 2 to 3 hours. The catch is staying consistent: manual querying doesn't scale, outputs change constantly, and you lose the trendline that makes measurement useful. Free works for a first pass; it's not a monitoring program.
Which AI models matter most for brand visibility in 2026?
For most B2B and B2C categories, ChatGPT, Perplexity, and Gemini cover the bulk of AI-assisted discovery. Perplexity is especially relevant because it cites sources and can drive referral traffic, not just awareness. ChatGPT has the biggest general-user footprint. Gemini matters most when your buyers live in the Google ecosystem. All three are worth covering if you want a complete picture of your AI brand visibility across the platforms shaping purchase decisions.
How long does it take to see improvements after optimizing for AI search?
Plan on 6 to 12 weeks to see meaningful movement in sentiment and accuracy, and 3 to 6 months for measurable gains in mention rate and citation frequency. Accuracy tends to improve sooner because it often comes down to specific content fixes that models can pick up relatively quickly. Mention rate usually takes longer because it depends on building authority across the sources LLMs lean on. Tracking your progress with consistent AI citation tracking is the only reliable way to know whether your AEO efforts are working.