
You can probably picture the meeting. It's late Friday, your content team is arguing about whether to implement llms.txt, and someone drops a LinkedIn post calling it "the robots.txt of the AI era." Another teammate waves around a thread insisting it's mandatory for GEO. The room lands on the easy answer: ship it Monday. Quick win. Except it's not a win. The "does llms.txt work" question now has real data behind it, and it's bad news for anyone pitching the file as an AI visibility lever.
Ahrefs published a study on June 15, 2026, analyzing 137,000 domains. The results should change how SEOs and GEO teams spend their hours. I'll stick to what the data shows, explain why the hype outran the reality, and point to the work that actually earns citations.
The Data Is In: The llms.txt Study Reveals a Solution Without a Problem
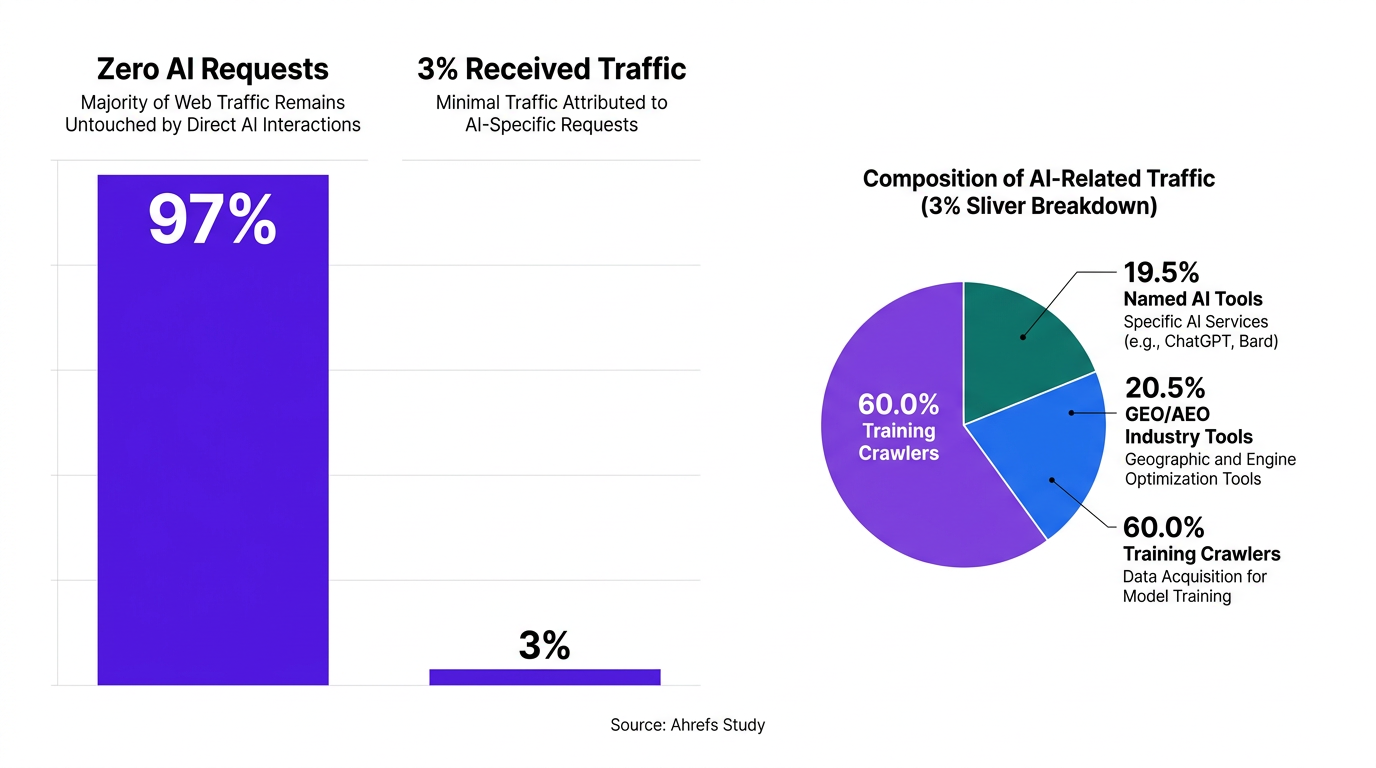
Ahrefs looked at roughly 137,000 domains for llms.txt adoption. About 28% had an llms.txt file, but that figure is inflated by who shows up in Ahrefs' dataset: customers tend to be more technical than the average site owner. Treat 28% as an upper bound, not a representative snapshot of the whole web.
The number you should care about is simpler: 97% of valid llms.txt files received zero requests in May 2026. No bots. No people. Nothing. The file sat there, untouched.
The remaining ~3% that saw any traffic doesn't rescue the narrative. Among those requests, 96% were bots, and only 19.5% of the read share came from named AI tools. The biggest requesters were GPTBot and Claude-Code, which are associated with coding and training crawls, not the retrieval systems behind AI search interfaces and the citations marketers track. One more detail matters: no AI bot ever requested a non-existent llms.txt file. In other words, these crawlers are not probing for the spec on sites that haven't published it.
Info: About 12% of llms.txt traffic came from the GEO/AEO industry itself: validator tools, researchers, and practitioners studying the phenomenon. The industry is partially generating the signal it's measuring.
That loop should make you uneasy. A noticeable share of the already-tiny traffic is us, refreshing the dashboard to see if the dashboard lights up. That's not adoption. It's the GEO community auditing its own homework.
So, Does llms.txt Work? A Brutally Honest Answer
No - not in the way most marketers mean it. If you shipped llms.txt expecting more visibility, more citations in AI answers, or any kind of llms.txt SEO boost, the evidence says it bought you nothing. It's not a visibility lever, and the crawl data makes that hard to argue with.
The reason it fails as a growth tactic is straightforward once you separate training from retrieval. LLMs are trained on the public web at scale. When an AI answer engine generates a response, its retrieval-augmented generation (RAG) system pulls from indexed, crawlable, high-quality content it can parse and cite. It doesn't need a special file to "discover" your site. It needs your pages to be legible to machines: clear claims, strong structure, and enough context to attribute information correctly. The llms.txt spec was proposed as a control mechanism, but its function is often misunderstood. While its name recalls robots.txt, llms.txt is designed to guide AI toward high-value content, not to block access. That's about inclusion, not exclusion. "I published a file" is not the same as "the model will cite me," and that confusion is doing real damage to GEO prioritization.
Adoption is optional, and there is no enforcement mechanism that forces AI companies to respect it (The AI Search Guy, 2024). Common Crawl has said it will support llms.txt directives in future crawls (Common Crawl, 2024), but that still doesn't make the file a switch you can flip to influence real-time citations inside AI search interfaces (ContentGrip, 2024). The industry keeps smearing training controls and retrieval behavior into one story, and teams end up optimizing the wrong thing.
Where the Real AI Visibility Battle Is Fought
If llms.txt isn't the answer, what is? The unglamorous stuff that keeps working: becoming the most citable source in your category. AI answer engines assemble responses from sources they can interpret, trust, and reference. Your job is to make your content the easiest option to pull from.
Note: This is where a visibility platform like Vizup becomes more useful than a technical file. It shows where your brand is cited, where competitors win mentions, and which pages need clearer structure or stronger authority signals. Vizup connects AI visibility to outcomes, helping you prioritize what to fix. To see how it works for your brand, book a demo.
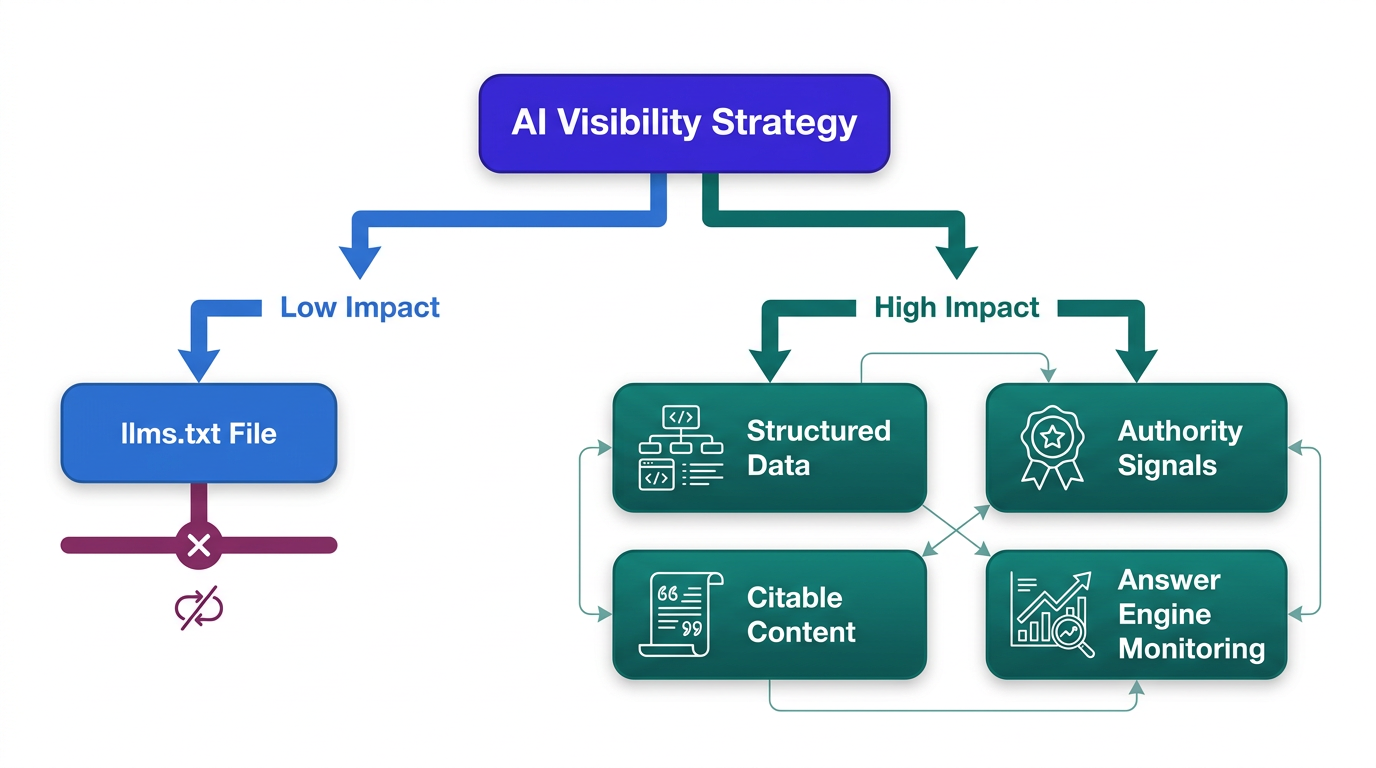
Make Your Content Machine-Readable
Start with the basics: semantic HTML that doesn't fight the parser. Clean heading hierarchies (H2s, H3s), descriptive lists, and direct phrasing make it easier for retrieval systems to lift the right passage. Then get serious about structured data. Schema.org turns your claims into explicit entities, facts, and relationships, which makes machine interpretation dramatically less ambiguous. If you haven't audited your key pages for structured data for LLMs, that's a better use of your time than polishing an llms.txt file that likely won't be requested.
Stop guessing and look at logs. Your AI crawler logs tell you which bots show up (including GPTBot), what they request, how frequently they return, and what they ignore. That's actual behavior, not vibes. If you want the context for why visibility metrics matter more than traffic, start by measuring crawl and citation reality instead of assuming traffic is the only scoreboard.
Build Verifiable Authority
Answer engines still need to trust sources, and trust still comes from familiar signals: real expertise, clear attribution, author bios with credentials, and content that cites its sources. What's changed is the evaluator. Machines apply these signals at scale, so weak attribution and fuzzy authorship don't just look sloppy - they become harder to classify and cite.
The most expensive myth in GEO is the idea that a technical trick replaces the grind of producing genuinely useful, well-sourced work. It doesn't. The teams earning citations are publishing content that would satisfy a skeptical human expert - because retrieval systems are trying to approximate that standard. If you want the longer version, our guide on improving brand visibility in AI search lays out what that looks like in practice.
The Counterargument: What About Future-Proofing?
To be fair, the best argument for llms.txt is that it's cheap insurance. You can create the file in ten minutes. If the spec ever becomes widely honored, you're not scrambling. That's a reasonable stance, and I'm not against publishing it.
The problem is the story teams tell themselves afterward. The risk was never the ten minutes - it's the misallocation that follows when "we shipped llms.txt" becomes a checkbox that stands in for actual AI visibility work. Based on current evidence, you likely created a file nobody reads. Meanwhile, your top 20 pages still don't have schema, author bios are thin or missing, and nobody has checked whether AI answer engines are citing you or handing the credit to competitors.
So treat llms.txt like low-risk hygiene. Put it in the same mental folder as your favicon and your security.txt. Then put your real effort into content quality and monitoring, because that's what moves citations.
Your AI Visibility Checklist for the Next 6 Months
Stop treating llms.txt adoption like a strategy. Put the hours here instead:
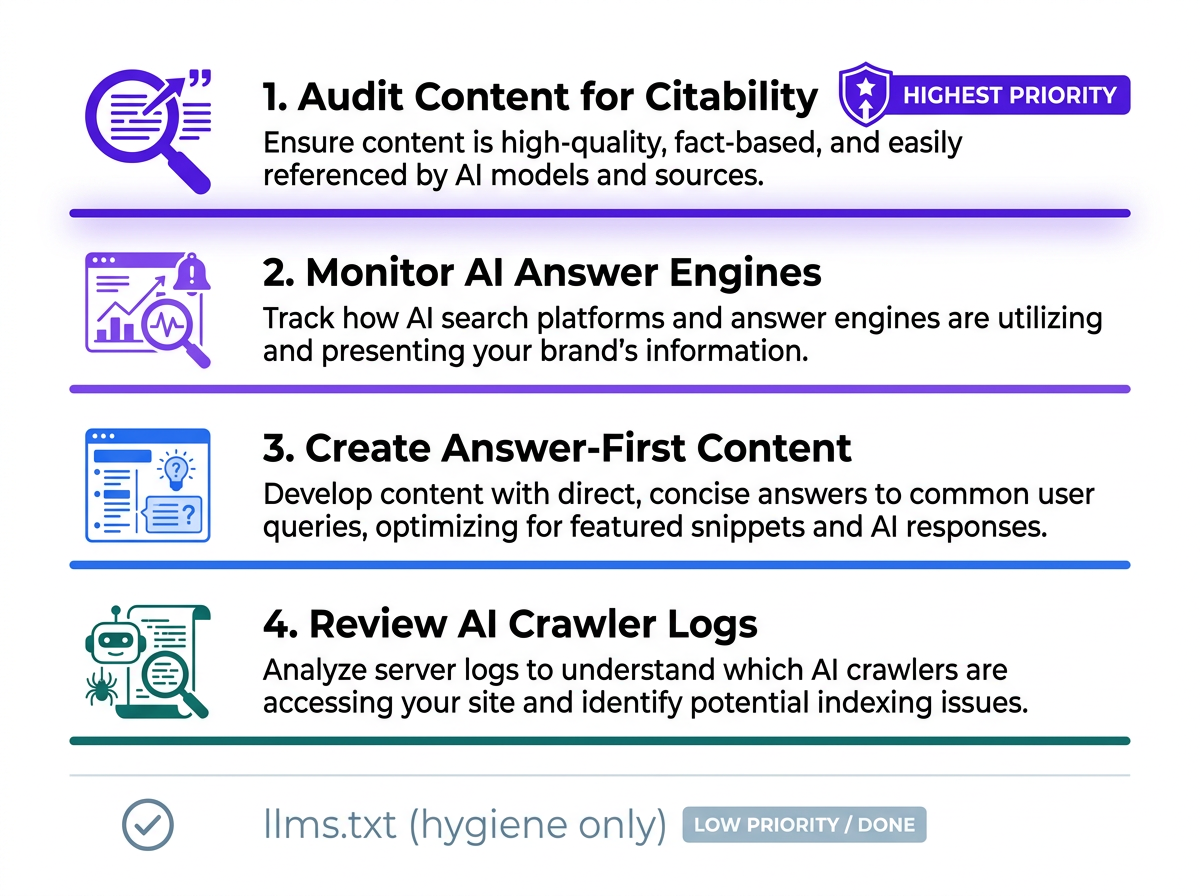
- Audit your top 20 content pieces for citability. Review heading structure, schema markup, source attribution, and whether each page answers a clear question directly. If a retrieval system pulled the page, would it extract a clean, trustworthy answer?
- Monitor your brand in AI answer engines. If you don't measure, you're just guessing. Use an LLM visibility tracking tool to see where you're cited, where competitors show up instead, and which questions you still don't cover.
- Create answer-first content. Stop spending cycles polishing metadata on old posts. Prioritize net-new pages that tackle specific user questions in structured, unambiguous formats - FAQs, comparison tables, and definitions that are easy to parse and reference.
- Review your AI crawler logs quarterly. Track which AI bots visit, what they crawl, and how often they return. It's the most direct evidence you have of bot behavior on your site.
If you want a fuller framework, the AI search visibility optimization playbook walks through these areas with implementation guidance.
Stop Reading the Instructions, Start Writing the Book
Fixating on llms.txt is like perfecting a table of contents for a book you haven't written. The value sits in the pages, not the front matter. The winners in the AI era won't be the first to adopt a spec; they'll be the most reliable, citable sources on the open web. That starts with content work you can ship this week.
Does llms.txt work as a visibility strategy? The data says no. Does clear, well-structured, authoritative content work? Every answer engine demonstrates that every day, every time it chooses a source to cite.
Vizup's Organic Autopilot is built for that reality. It helps you monitor presence across AI answer engines, spot content gaps, and optimize for the clarity and authority that earns citations across Search, Social, Communities, AI Answer Engines, and Local Discovery. If you're ready to drop the hype and focus on execution, book a demo to see what organic-first AI visibility looks like in practice.
Frequently Asked Questions
What is llms.txt and what is it supposed to do?
llms.txt is a proposed standard meant to give site owners a way to control which parts of a site can be used for training large language models (Search Engine Land, 2024). It uses 'User-agent' directives plus 'Allow'/'Disallow' path rules, similar to robots.txt (The Webmaster, 2024). The intent is access control for training data, not promotion or visibility.
Does Google or OpenAI require an llms.txt file?
No. Google and OpenAI do not require llms.txt. Adoption is voluntary, and there is no enforcement mechanism that compels AI companies to honor the file. Google's crawlers and OpenAI's GPTBot crawl the public web whether or not llms.txt exists.
If llms.txt doesn't work for SEO, what should I do for AI visibility instead?
Put your effort into citability: pages with clean heading hierarchies, schema markup, clear author attribution, and direct answers to specific questions. Then measure outcomes by monitoring your brand in answer engines using best LLM visibility tools, and keep publishing answer-first content that retrieval systems can parse and reference.
Is there any harm in creating an llms.txt file?
The file itself is low-risk and quick to publish. The downside is organizational: treating it as meaningful AI visibility work and stopping there. If you ship llms.txt as basic technical hygiene and then focus on content optimization and monitoring, you're fine.
How can I see if AI bots are crawling my site?
Check server access logs for user-agent strings from known AI crawlers like GPTBot, ClaudeBot, and Googlebot. Many hosting platforms and CDNs provide log analysis that can filter by bot type. If you want ongoing tracking, a dedicated AI visibility platform can monitor crawler behavior alongside citation performance in answer engines.