The push to publish a parallel markdown version of your site "for AI" is one of the stickiest bad habits in technical SEO right now. It sounds tidy: LLMs like text, markdown is tidy text, so ship markdown. But Google's Martin Splitt and John Mueller tackled the idea head-on on the Search Off the Record podcast, and they didn't hedge. Markdown-only pages are bad UX (no layout, color, or structure), parallel versions double your maintenance surface area and drift out of sync in ways machines won't flag, and ideas like llms.txt still don't have a reliable way to get discovered. Their bottom line: invest in your structured HTML. Don't build a bot fork.
Using markdown for AI search is a fix for a problem you don't actually have. It burns developer time, weakens the signals your real pages already carry, and runs against the direction Google has been pointing for years. The teams that win in AI search will not be the ones running a simplified shadow site. They'll be the ones who made the main site so legible and well-structured that an alternate version never mattered.
The Siren Song of 'AI-Optimised' Simplicity
I get why this idea keeps coming back. Every few weeks, it pops up in a developer forum or a client Slack: "Should we build a markdown version of our site for AI search?" The logic is familiar: LLMs tokenize text, HTML is "noisy," and markdown removes the noise, so markdown must be better for AI. The argument has some technical basis: Markdown is a lightweight plain-text format, and the IETF registered text/markdown as a media type in RFC 7763. In controlled LLM workflows, cleaner text representations can be easier to process than raw, markup-heavy documents. But that does not mean brands should publish a separate markdown version of their public website.
That technical intuition — cleaner text, easier parsing, fewer distractions — helps explain why llms.txt caught on.. The llms.txt proposal is a Markdown-formatted file meant to give Large Language Models a curated map of a site's most important resources. The motivation is reasonable: make it easier for machines to find the good stuff. The problem is that "machines like markdown" isn't a content strategy. The real question is whether a parallel markdown site earns its keep once you account for cost, risk, and ongoing trade-offs. Google is saying it doesn't.
Google's Verdict: Stripped-Down Content is a Dead End
When Splitt and Mueller talked about this on Search Off the Record, it wasn't a throwaway comment. They were responding to a real trend: "AI-optimised" playbooks that split a website into a human version and a machine version. Their critique lands in three places, and any one of them should be enough to stop the project.
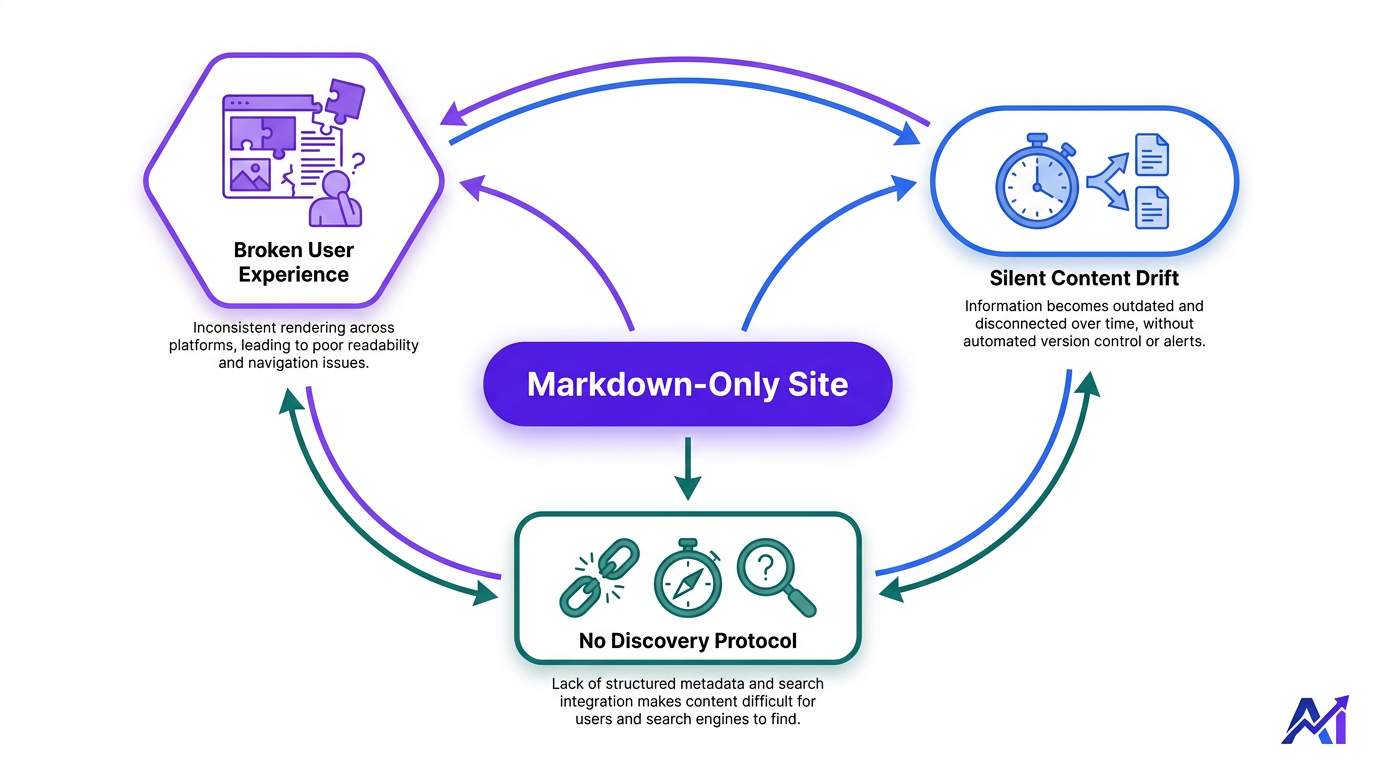
It's a Terrible User Experience
Splitt's point was simple and brutal: a markdown file doesn't have layout, navigation, brand cues, or interactive elements. If a user (or an agent acting for a user) lands there, the page is effectively broken. Nielsen Norman Group's foundational definition of UX is broader than "can you read the words"; it covers the full interaction a person has with a company and its products. A raw.md file with no styling, no hierarchy, and no navigation fails that bar. Google is in the business of sending people to useful, accessible pages. It is not going to enthusiastically funnel traffic, from classic results or Google's AI-powered search, to something that looks like a text dump.
The Silent Breakage of Parallel Content
This is the part that should make technical SEOs nervous. Two versions of the same content means every edit now has two targets: every product update, every pricing change, every legal tweak, every typo fix. In the real world, the HTML gets updated because customers see it. The markdown copy lags behind. The nasty bit is how it fails: quietly. No 404. No console error. The file still returns perfectly valid text - just the wrong text. Outdated pricing, retired features, old legal language. You end up feeding stale information to the systems you were trying to impress.
Warning: A markdown file that silently serves outdated information is worse than having no markdown file at all. At least with no file, crawlers fall back to your canonical HTML, which is current.
The Discovery Problem No One Solved
Say you accept the UX hit and you promise to keep both versions current. You're still stuck on a basic plumbing question: how does anything reliably find these markdown files? llms.txt exists, but it has no standard discovery path. It isn't part of robots.txt. It isn't baked into sitemap schemas. It's a convention people are trying out, not a spec the ecosystem has adopted. Vizup's own research found that 97% of llms.txt files are never read by the crawlers they were meant for. You can craft the cleanest, most careful llms.txt index imaginable and still end up with a file that sits on your server doing nothing.
The Markdown vs HTML AI SEO Debate, Settled
So, on the markdown vs HTML AI SEO question: HTML wins, and it isn't subtle. The markdown pitch usually assumes crawlers are overwhelmed by HTML. Modern crawlers aren't. Googlebot, Bingbot, and the crawlers feeding systems like Gemini and ChatGPT are designed to parse complex HTML at scale. More than that, they use it. Headings, lists, tables, schema markup, ARIA labels - those are the cues that tell a machine what matters and how ideas relate. Strip that away and you don't make the page easier to understand. You remove the structure the machine depends on.
Google's published guidance still rewards high-quality, people-first content that demonstrates E-E-A-T (expertise, experience, authoritativeness, and trustworthiness), regardless of how the content was produced (Google Search Central, 2024). There's nothing in there that hints you should publish a simplified machine-only variant. As Google's official AI search guide lays out, AEO and GEO are still just SEO with a new set of surfaces. If you want AI search visibility, the work happens on your existing pages, not on a sidecar site you hope a crawler notices.
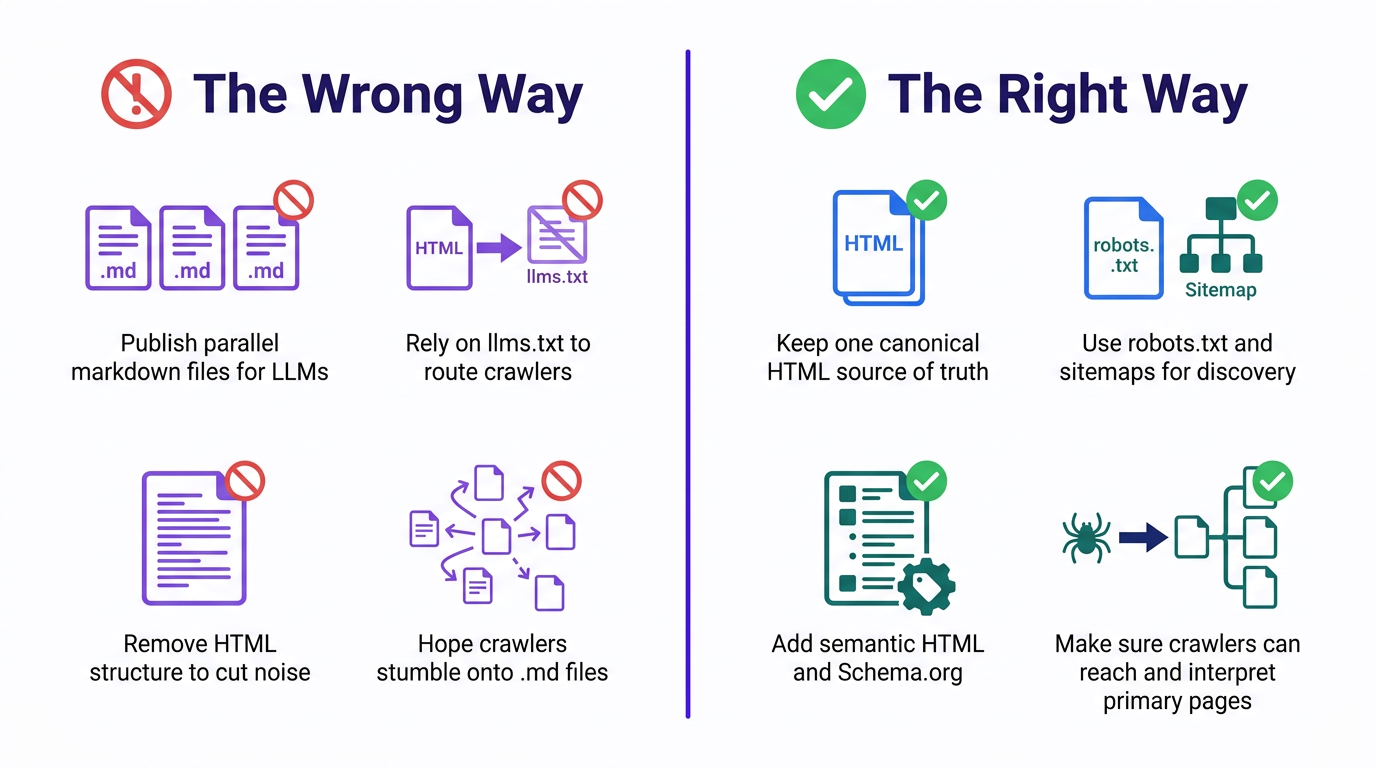
| The Wrong Way | The Right Way |
|---|---|
| Publish parallel markdown files for LLMs | Keep one canonical HTML source of truth |
| Rely on llms.txt to route crawlers to markdown | Use robots.txt and sitemaps for discovery |
| Remove HTML structure to cut "noise" | Add semantic HTML and Schema.org |
| Chase token efficiency for ingestion | Chase clarity for humans and machines |
| Hope crawlers stumble onto.md files | Make sure crawlers can reach and interpret primary pages |
| Every action in the left column creates work. Every action in the right column compounds existing value. |
Addressing the Counterargument: But Markdown IS More Efficient
The efficiency argument isn't imaginary. The IETF registered text/markdown as a media type in RFC 7763 back in 2016, and the format is genuinely useful in the right contexts. The token-reduction numbers are real. If you're building an internal RAG pipeline or pushing documents through a fine-tuning workflow, converting HTML to markdown before ingestion is a sensible engineering move.
Just don't confuse internal processing with public publishing. The moment you serve markdown as a crawlable alternative to your HTML pages, you sign up for the maintenance trap described above. And the token savings mostly accrue to the LLM provider, not to your site architecture. Google, OpenAI, and Anthropic already run their own pipelines to convert and process the HTML they crawl. You don't need to pre-chew your site for them, and they haven't asked you to.
What to Do Instead: Fortify Your Primary Site
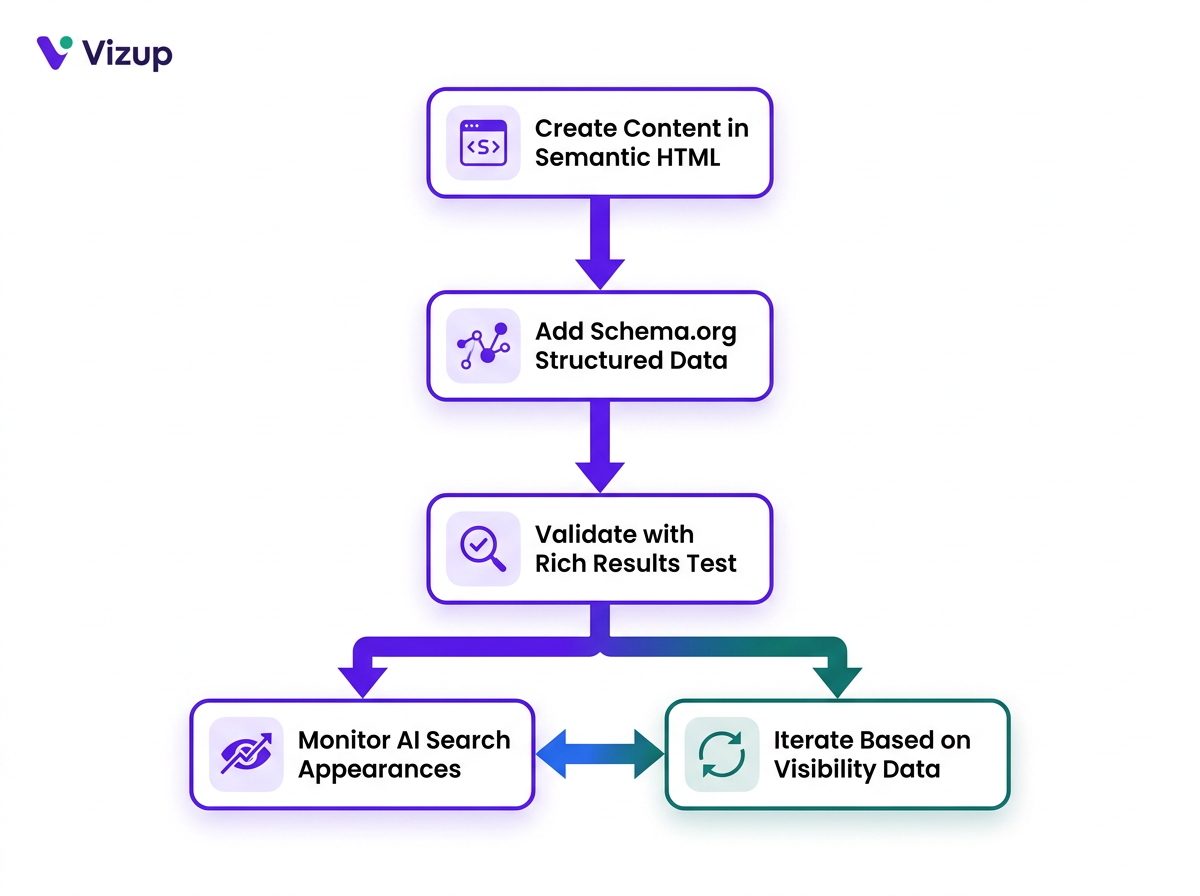
The better path is boring on purpose: make the one good page better. You don't need a new format or a parallel workflow; you need to tighten the signals your existing pages already send, with AI systems now part of the audience. Use semantic HTML5 elements (article, section, nav, aside) so machines can identify the page's anatomy. Add Schema.org structured data to spell out entities, relationships, and facts. Write plainly, and organize the page under descriptive headings that match how people scan. Keep an eye on content aligns with user preference in search, because that is what both classic ranking and AI-driven systems tend to reward.
Tools like Vizup's digital presence monitoring can show how your pages show up in AI-generated answers, which gives you a way to measure whether structural improvements are paying off. That's a feedback loop worth funding. A markdown shadow site, by contrast, is mostly busywork with no dependable signal.
How Vizup Turns This Into an Organic Discovery System
The practical alternative to a markdown shadow site is not another technical workaround. It is a stronger organic operating system.
Vizup works as an Organic Autopilot for modern discovery, helping brands monitor, create, optimise, publish, and learn across Search, Social, Communities, AI Answer Engines, and Local Discovery. Instead of splitting content into human and machine versions, Vizup helps teams improve the canonical assets that already matter: pages, answers, citations, entity signals, local visibility, social proof, and topic coverage.
The platform combines AI agents, human experts, and live SEO, pSEO, AEO, and GEO tools so brands can see how they are being discovered, where they are missing from AI-generated answers, what content needs to be strengthened, and which pages should be updated next. Paid ads can be added as amplification, but the core advantage is organic: building a discoverable, trusted presence that compounds across every surface where customers now search.
Stop Forking Your Content, Start Fortifying It
A separate markdown site for LLMs is a distraction dressed up as progress. It runs against Google's explicit guidance, adds silent failure modes, and "solves" work that LLM providers have already handled on their side. The future of AI optimised content is still a single canonical page: well-structured HTML that serves humans and machines without hacks. Google's guidance points strongly in that direction: improve the primary page instead of creating a machine-only fork. The teams that do well in AI search will be the ones who made their primary site authoritative and easy to parse, not the ones who shipped a clever workaround and hoped it stayed in sync.
Frequently Asked Questions
Is markdown better than HTML for SEO in the age of AI?
No. Markdown can be more token-efficient for LLM processing, but HTML carries the semantic structure, schema markup, and layout signals that traditional and AI search systems use to interpret a page. Strip those signals and the content usually becomes harder for machines to understand, not easier. If you're choosing between the two for public pages, well-structured HTML is the stronger bet.
Does Google recommend creating a separate markdown version of a site for its crawlers?
No. Martin Splitt and John Mueller addressed the idea on the Search Off the Record podcast and warned about three issues: markdown-only pages are bad UX, parallel versions drift and fail silently, and there is no established discovery mechanism. Their advice is to improve your existing HTML rather than fork your content.
What is llms.txt and should I use it to point to markdown files?
llms.txt is a proposed Markdown-formatted file meant to guide LLMs to a site's most important resources. The catch is that it still lacks a formal discovery protocol, and research indicates 97% of these files are never read. For most sites, the effort is better spent on semantic HTML and structured data.
How can I make my content 'AI-optimised' without creating parallel content versions?
Stick to the fundamentals: semantic HTML5, Schema.org structured data, clear writing under descriptive headings, and crawlability via robots.txt and XML sitemaps. Those are the same practices that support traditional SEO, and they're also what AI systems use when extracting and citing information. Read more in Google's official AI search guide.
What's the risk of maintaining a separate markdown site for AI search?
Silent content drift. When you maintain two versions, the markdown copy tends to fall behind the canonical HTML. Unlike a broken link or server error, outdated markdown usually produces no obvious failure. It just serves incorrect information to crawlers, which can then surface in AI-generated answers about your brand.